The Day I Learned That “Remove” Doesn’t Mean Remove
When I started contributing to Flatseal through the Igalia Coding Experience program, I expected to spend most of my time writing code.
I quickly discovered that I was wrong.
Over the past few weeks, I’ve been working on two seemingly unrelated areas of Flatpak permissions: conditional permissions and USB permissions. On paper, they looked like straightforward tasks. One involved understanding a relatively new Flatpak feature, while the other appeared to be a bug fix in Flatseal.
What I didn’t expect was that both tasks would teach me the same lesson: understanding the semantics of a system is often harder, and more important than writing the code itself.
Flatseal is a GNOME application that provides a graphical interface for managing Flatpak permissions. It gives users visibility into what applications can access and allows them to modify those permissions without manually editing override files.
At first glance, permissions seem simple. An application is either allowed to do something or it isn’t.
The reality is far more nuanced.
One of the first areas I explored was Flatpak’s conditional permissions. These permissions allow an application to request access only when certain runtime conditions are met.
Initially, I thought of permissions as static declarations. An application requests access to a resource, and Flatpak either grants it or denies it.
Conditional permissions challenge that assumption.
Instead of saying “always grant this permission,” an application can say “grant this permission only if a particular condition is true.”
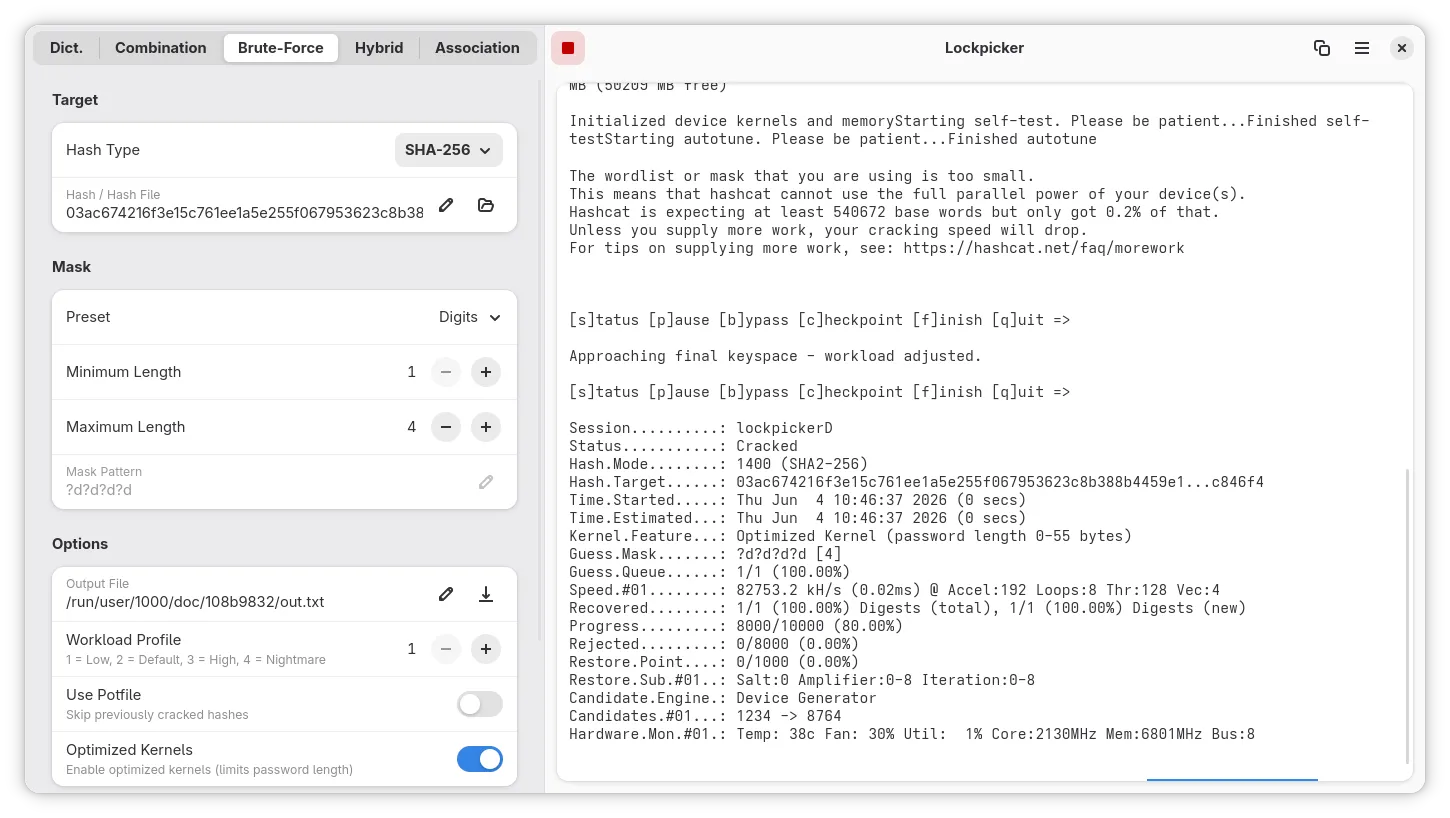
 The override file showing a conditional permission: if:x11:!has-wayland grants X11 access only when Wayland is unavailable.
The override file showing a conditional permission: if:x11:!has-wayland grants X11 access only when Wayland is unavailable.
The more I learned about the feature, the more I realized that permissions are not always permissions. Sometimes they are fallback mechanisms. Sometimes they are compatibility layers. Sometimes they exist purely because different systems support different capabilities.
This raised an interesting question for Flatseal.
If a permission only applies under certain conditions, how should that be represented to users? Should it be visible? Should it be editable? Should the interface expose the raw configuration or explain the effective behavior?
Those questions had less to do with coding and more to do with understanding the intent behind the feature.
While I was still thinking through those questions, I moved on to USB permissions.
That was when things became even more interesting. Flatpak exposes two related USB concepts:
-
-
- Allowed USB devices
- Blocked USB devices
-
These are represented internally through enumerable-devices and hidden-devices.
At first, this seemed straightforward. A device is either allowed or blocked. Then I started experimenting with flatpak override.

Flatseal’s USB section
I discovered that the same USB device can appear in both lists at the same time. Not only is this valid, but it is an expected configuration.
The key detail is that the hidden list always wins.
A device can be present in the allowed list and the blocked list simultaneously, and Flatpak will still treat it as blocked.
That discovery completely changed how I thought about the problem.
The original bug I was investigating involved removing USB devices through Flatseal’s interface. My initial assumption was simple: if a user removes a device from the allowed list, then the device should no longer be allowed.
-
-
- But what does “remove” actually mean?
- Does it mean deleting an override?
- Does it mean explicitly blocking the device?
- Does it mean restoring the original application defaults?
-
The answer depends on where the permission came from in the first place.
An original permission declared by an application is different from a permission added by the user. Removing those two things should not necessarily produce the same result.
What looked like a small UI interaction suddenly became a question about semantics.
I found myself spending more time reading source code, experimenting with Flatpak commands, and discussing expected behavior with maintainer and my mentor, Martin Abente, than writing actual implementation code.
At one point, I realized that I had been approaching the problem from the wrong direction entirely.
I was asking: “How should I implement this?”. The better question was: “What behavior is Flatpak trying to express?”
Only after answering that question could I determine how Flatseal should behave. That shift in mindset has probably been the most valuable lesson of this experience. As developers, we often think of programming as the process of building things.
Increasingly, I’m learning that a significant part of software engineering is understanding things.
-
-
- Understanding why a feature exists.
- Understanding the assumptions behind a design.
- Understanding what users expect to happen.
- Understanding what maintainers intended years before you ever opened the codebase.
-
The code is often the final step. The real work happens before that.
Looking back, neither conditional permissions nor USB permissions taught me the most important lesson. The lesson was that software behavior is defined by semantics, not implementation details.
A user clicks “remove” and expects a particular outcome.
A maintainer designs a feature with a specific meaning in mind.
A system applies rules according to semantics that may not be obvious from the UI.
Bridging those perspectives is where much of the engineering happens. And that’s exactly what has made contributing to Flatseal such a rewarding experience.
I started this journey expecting to write code. Instead, I learned how to ask better questions.
Ironically, that has probably made me a better engineer than the code itself ever could