The latest version of Typesetter updates the built-in Typst compiler to version 0.15, which brings a long-awaited feature: variable font support – no more warnings and faulty font rendering when using your system’s default fonts. This release also adds a popularly requested feature to the editor: manual font size adjustment – use the standard keyboard shortcuts to make the text larger and smaller.
Hello everyone! I’ve just released new updates for ChromaLeon, my extension that extracts and applies colors from your wallpaper to your GNOME Shell and LibAdwaita theme.
The focus of these updates was refinement: the color extraction system is now smarter, ensuring better compliance with WCAG accessibility guidelines regarding contrast. Additionally, I’ve improved the icon generation system (folders and apps) to make it much faster and more efficient, now generating icons almost instantly.
Create custom time-of-day schedules for the Night Light!
Night Light Scheduler lets you create a custom schedule for GNOME’s built-in Night Light allowing you to automatically adjust the color temperature throughout the day according to your schedule.
Features:
Create a schedule to automatically adjust Night Light color temperature throughout the day
Smoothly transition between temperatures with an adjustable transition time
Import and export schedule configuration as an editable .ini file
Uses GNOME’s built-in Night Light functionality
Easy to use visual interface
More information is available on the project’s GitHub page.
This week, we released for Damned Lies a new feature for team coordinators. When updating your team details, you can now create a presentation that will be sent to new team members as a notification. Use it to present the team, the workflow, link your docs, identify a module for newcomers…
Five weeks into GSoC 2026, I’ve made solid progress on GPU reset recovery in Mutter!
When a GPU reset occurs, Mutter currently has no way to recover; the desktop either freezes or crashes. My project implements a recovery path: detecting the reset, waiting for it to complete, recreating the context, and propagating that change through the compositor to recreate resources so rendering can resume.
The display now comes back after a reset, and the session remains usable, though there’s still work ahead: notably, automatic framebuffer recreation and fixing the desktop background, which currently renders with garbled textures after recovery.
Over the past few weeks, I have been writing the backend for the vocabulary-puzzle generator for Crosswords.
But what entirely dictates a valid word placement whilst being mindful of all edge cases and managing the state of the puzzle upon the exploration of possible solutions?
Finding valid intersections
For each word in the list, the vocab generator searches for every valid location where the word at the current depth could be added (or not added) to the current puzzle. A candidate must satisfy several constraints:
Word must intersect existing puzzle.
Intersecting characters must match.
Existing letters must not be overwritten by conflicting letters.
The word is within a 30×30 board boundary.
Puzzle remains entirely connected.
Word placements cannot connect flush to their head/tail to another word.
Could there be multiple valid intersections?
As more words are added, the number of possible intersections rapidly grow. A single placement may produce several valid connections, each of which must be evaluated independently.
Modeling the intersections
The vocab grid generator represents candidate placements by using the coordinates of the intersection, placement direction (across, down), and the offset of the intersecting character within the word. As a whole, an intersection can transform the entire puzzle. For instance, “APPLE” and “PEAR” are just two words, but share four possible intersections. Rather than selecting one immediately, we ultimately want to record every valid candidate.
Each of these shared candidates then become a potential node in our recursive search tree. As our puzzle grows in size, the problem becomes less about placing words and more about exploring all valid intersections whilst preserving the integrity of the puzzle state as we add and rearrange words.
As is the case for many people working in the security industry, the last
few months of my life have been focused on dealing with people wanting to
use LLMs everywhere. From an enterprise security perspective that’s not an
inherent problem - what’s more of a problem is that people want those agents
to have access to resources like their calendar and email and so on, and now
we have somewhat non-deterministic agents that seem very enthusiastic to
achieve what you asked whether that’s a good idea or not, and we’re
combining this with credentials that give them access to sensitive data, and
leaving those credentials on disk where they can be committed into git repos
or exfiltrated to some other service to make use of them on the agent’s
behalf or well just any other number of things, at which point your CEO’s
email is suddenly readable by everyone and you’re having a bad day.
As I mentioned in my last
post, pretty
much every strong mechanism for keeping credentials in place is just not
supported in the wider world. We can imagine a universe where agents use
hardware (or at least hypervisor) backed certificates to obtain credentials
and any that end up leaking are worthless as a result. But, sadly, that’s
not an option for most people using existing identity providers. The state
of the art is that you use the device code
flow and a human authenticates and
the token ends up back inside the agent environment and then it proceeds to
do whatever it wants with it and you just hope that you wake up the next
morning without an awful infoleak occurring.
(An aside: I do not like the device code flow as used in enterprise
environments, and I never will. The identity provider doesn’t have a real
opportuity to inspect the security posture of the system asking for the
token, and as a result some identity providers will restrict tokens that are
issued in this way. The common alternative of doing stuff using a more
standard flow and having a redirect URI pointing at localhost works fine for
local systems and is a pain for remote ones, even if you can commit crimes
with SSH forwarding. I’m going to suggest something that I think is better,
and you are free to disagree)
I’m not in a position to get every identity provider and service provider to
change their security posture, so I’m somewhat stuck in terms of the tokens
they’re willing to issue me - largely either JWTs or opaque access tokens,
with no support for any mechanism of binding that token to an instance. The
token that’s going to have to be provided to the remote service is something
I have little influence over. But that doesn’t mean I can’t influence the
token that lands inside the agent’s environment. I can issue a placeholder
token to the agent, and force it to communicate via a proxy that swaps out
the placeholder for the real thing. The worst the agent can do is exfiltrate
the placeholder token, and as long as malicious actors don’t have access to
that proxy, it doesn’t matter - nobody else can do anything with the
placeholder.
This isn’t a terribly novel insight, and it seems like almost everybody has
reinvented this on their own. But a lot of these implementations involve you
somehow obtaining the real token in advance and then pasting that into
something that generates a placeholder that you provide to your agent
environment somehow, and it’s all a bit clunky and awkward, and it also
means that you need to deal with something that keeps track of the mapping
between placeholders and real tokens and oh no we’ve just invented a secret
store, and if you want this to work at scale and reliably you’re just
invented a high availability distributed secret store, and a lot of people
who’ve read that are now shaking their heads and reaching for gin. Can we
simplify this, and improve security at the same time? I think we can!
Remember when I said “as long as malicious actors don’t have access to that
proxy, it doesn’t matter”? What if they do? What if they compromise one
machine inside your environment and are then able to email a bunch of
employees and convince their agents to send more tokens back to them and
then delete the email before a human reads it? Now you have someone inside
the wall with access to those tokens, and presumably with access to the
proxy, and now they can be anyone whose agent was gullible enough to think
sending them a token was a good idea. This isn’t good!
So, I thought for a while, and I came up with a new idea. We can have a
broker service that obtains credentials for us. We can run that centrally,
away from the agents. A client in an agentic environment can request a
token, and that can result in a URL being generated and the user being
directed to open a URL in a browser and authenticate. When the user
authenticates, the authentication flow redirects the confirmation back via
the broker, and the broker obtains the real auth token. The obvious thing to
do now would be to return the auth token to the client in the agentic
environment, but we don’t do that. Instead, we mint a new JWT, and add a new
claim - one that contains an encrypted copy of the token. In the process we
can copy over all the original claims, because those aren’t secret - and now
even if the client inspects the token to figure out what access it has,
it’ll get a correct answer. We sign the new token with our own signing key,
and pass that back to the client. The client now has a legitimate JWT that
is utterly useless, because the signature isn’t trusted by anyone other than
us.
How does it use it? It makes an API request via a proxy, including the new
token in the Authorization: header. The proxy verifies the signature on the
token, and then decrypts the original token and swaps out the fake token for
the real one. The remote API sees what it expects, and everyone is
happy. There’s never a real token in the agentic environment, but also we
don’t need to store anyting anywhere. The only state is the encryption keys,
and those can be injected into the environment at startup. You need to
scale? Just start more of these processes. You need to support multiple
availability zones? Just start more of these processes in different
places. No persistent data is ever held in the broker or the proxy. You
don’t need to care about distributed databases or secret stores.
This felt wonderfully elegant and I felt smug about coming up with a better
idea, and then I went to a bar earlier this week and sat down to read RFC
8705 and the guy next to me
saw that over my shoulder and asked what I was reading and I explained why I
was interested and we talked about agentic identity and then he mentioned
that fly.io had something that sounded very
similar and I read that and gosh yes
it is very similar, so damn you fly.io for stealing my ideas 3 years before
I even had them. Anyway. Now I need to do better.
Remember that there’s still a risk around anyone who has access to the proxy
having access to the encrypted keys? We can remove that risk as well. It’s
not uncommon for agentic environments to have an identity issued via
something like SPIFFE, at which point they have a
client certificate. You can probably guess where I’m going with this. If we
require that an agent present a client cert to the broker when requesting a
token, we can embed a representation of that client cert into the token we
mint. The proxy can then require mTLS for the client connection, and can
verify that the presented certificate matches the one represented in the
token. If it does then whoever’s using the token has access to the private
key associated with the environment it was issued to. If we then ensure that
the private keys backing these certificates are either hardware or
hypervisor backed, and as such tied to a specific instance, we now have a
high degree of confidence that the token can only be used in its intended
environment. Even if our identity provider doesn’t support RFC 8705, we can.
This is fairly straightforward where you’re using a platform where your
identity provider is also the environment that’s consuming your tokens, and
more annoying for third parties. The broker potentially needs some amount of
third party vendor knowledge to make that work for everyone. This is even
more the case where login isn’t via your identity provider (thanks, github),
but none of this is insurmountable - just annoying. And where vendors issue
opaque tokens rather than JWTs, this still isn’t a problem; we can just mint
a new JWT that includes the opaque token as an encrypted claim, and include
the same certificate binding. The opaque token ends up being the thing
that’s presented to the third party, but only after we’ve verified the mTLS
binding.
In an ideal world none of this would be necessary - someone would spin up a
new agentic environment, a user would prove their identity, and a
certificate embodying that identity would be issued to the environment with
a private key that can’t be exfiltrated. That certificate would be
sufficient to obtain new certificates associated with the same private key,
and we could still bind that into mTLS identity. This would be much simpler,
but browsers don’t support it, so it’s not likely to happen any time soon.
Anyway. Even if we can’t have the best thing, we can do better than we are
at the moment, and also it would be lovely if we could standardise on this
rather than have everyone build their own thing. The end.
It’s overdue, but here is my first progress update. If you haven’t read my introductory post, the short version: I’m implementing GPU reset recovery in Mutter, the Wayland compositor at the heart of GNOME Shell. When the GPU encounters a hardware- or driver-level fault and resets, invalidating the EGL context and wiping out all allocated GPU memory, Mutter currently has no way to recover. My project aims to change that.
Here is where things stand at the time of this writing:
Graphics reset recovery demo
After a period of normal operation, a reset is triggered: the display goes dark, then comes back once a new framebuffer is created (currently triggered manually by maximizing the active window via a keyboard shortcut). Windows are rendering, input works, the session is alive. You’ll notice the desktop background looks wrong after recovery; I’ll explain why later in this post. The compositor itself, however, is no longer dead.
The Problem
A GPU reset is the hardware’s way of recovering from a hang or fault in the graphics pipeline. For the rest of the system, it means the GPU’s state has been wiped: any GL context that existed before the reset is invalid, and all GPU-allocated memory (textures, framebuffers, shader programs, etc) is lost.
Mutter’s fundamental problem is that it doesn’t create a robust GL context. While Mutter does call GetGraphicsResetStatus() as part of its existing rendering logic, without opting into the appropriate reset notification mechanism, that call will never return a reset status, even when one has occurred. Mutter (on main) simply has no way to detect a GPU reset, let alone recover from one.
The consequences in practice are severe. On some drivers (notably Mesa’s radeonsi/amdgpu), the driver deliberately kills the process when a non-robust GL context is present for a GPU that was reset. On others, Mutter would continue rendering blindly against an invalid context, with monitors on the affected GPU frozen on the last frame before the reset. GL errors accumulate on every subsequent frame, and the only way out is to kill the process. Either way, the session is lost, along with every application running within it. This has been a known, long-standing issue.
The Foundation
The API that makes detection and recovery possible is provided by the EXT_robustness OpenGL ES extension and its EGL counterpart, EXT_create_context_robustness. By specifying the EGL_CONTEXT_OPENGL_RESET_NOTIFICATION_STRATEGY attribute with the value EGL_LOSE_CONTEXT_ON_RESET at context creation, we opt into deterministic reset notification: GetGraphicsResetStatus() will now reliably return a reset status when one has occurred, and the context is invalidated in a well-defined manner. Additionally, GetGraphicsResetStatus() can be called repeatedly with the lost context itself and will return NO_ERROR once the reset has fully completed, which is precisely how we know when it is safe to attempt restoration. It’s worth noting this isn’t universally available: not every driver implements reset notification, and even where the EGL/GL layer supports it, actual reset detection depends on cooperation from the kernel driver. Robustness is something we can build on, not something we can assume.
Before GSoC began, Robert had already laid the groundwork for this. His commit did the following:
Registered EXT_create_context_robustness as a Cogl EGL winsys feature, so that its availability can be queried at runtime.
Added EGL_CONTEXT_OPENGL_RESET_NOTIFICATION_STRATEGY and EGL_LOSE_CONTEXT_ON_RESET to the attribute list at context creation, when that feature is available, creating a robust context for the first time.
Added a stub clutter_backend_reset_context() as the hook where recovery logic would eventually live. For the time being, it simply emitted a warning.
Wired up the detection path in meta_compositor_real_after_paint(); whenever GetGraphicsResetStatus() returned a reset status, the stub was called.
He also added support for simulating GPU resets in Mesa’s llvmpipe software renderer (MR !40681). By creating or modifying a file at a path specified by the LP_CONTEXT_RESET_FILE environment variable, all llvmpipe contexts using the LOSE_CONTEXT_ON_RESET strategy that were created before that file start reporting a reset; contexts created afterwards correctly report no error. Without this, the only way to test would be to induce actual hardware or driver failures, which is considerably less convenient.
The Recovery Cycle
The naive first instinct, which is to detect the reset, immediately recreate the context, and resume rendering, does not work, and for a subtle reason: a GPU reset is not instantaneous. After GetGraphicsResetStatus() first returns an error, the hardware may still be in the process of resetting. Attempting to recreate the context mid-reset invites further failure, and so the correct approach is to wait for the reset to complete before attempting any restoration.
This led to designing the recovery as a cycle with two phases, Reset and Restoration, tracked by a set of five states:
Graphics reset recovery cycle
All of this state management currently lives in ClutterBackend, with initial reset detection in ClutterStageView‘s frame handler. When GetGraphicsResetStatus() first returns an error, the state transitions to RESET_IN_PROGRESS and a GLib timeout source begins polling for reset completion every 20 milliseconds. Once GetGraphicsResetStatus() returns NO_ERROR, indicating the hardware has finished resetting, we move to RESET_COMPLETED. If the reset takes longer than 2 seconds, we proceed to restoration anyway; empirically, if a reset is going to complete, it does so quickly.
The restoration phase runs entirely outside the frame dispatch loop, using GLib idle and timeout sources. When this starts, the state transitions to RESTORING. Thanks to Jonas, an important lesson from an earlier implementation was that restoration must not happen during frame dispatch, because that code runs per monitor; you do not want to recreate the EGL context for every connected display.
During recovery, every frame dispatch is aborted. The frame handler signals to the frame clock that the frame should be dropped without scheduling a replacement. This check occurs both at the beginning of the frame handler, before any rendering occurs, and at the end, to catch resets that occur mid-frame.
If restoration fails and retries exhaust a 2-second timeout, the state transitions to FAILED and Mutter exits gracefully with a descriptive error message, rather than aborting or hanging indefinitely.
Restoring The Graphics Pipeline
Once RESET_COMPLETED is reached, restoration begins. The core of it lives in clutter_backend_restore_graphics(), and the sequence is:
Unref and destroy the current CoglContext.
Tear down the CoglDisplay, destroying the underlying EGLContext.
Re-setup the CoglDisplay, creating a fresh EGLContext.
Create a new CoglContext against the newly set up display.
Emit ClutterBackend::graphics-reset to notify everything else.
Step 2 required a small new addition to Cogl: cogl_display_destroy(). Previously, there was no way to tear down a CoglDisplay‘s contents without destroying the object itself, which would have invalidated references to it held throughout the codebase. The function calls the object’s destroy() implementation and marks it as no longer set up, leaving the object intact and ready to be re-setup.
Straightforward in isolation, but the interesting work is in everything that happens at step 5.
Propagating the reset through the compositor
ClutterBackend::graphics-reset is the hook through which the rest of the compositor learns that a new EGL context exists and needs to respond. Several objects connect to it, and the order in which their handlers run matters significantly.
The current sequence, enforced through the use of the G_CONNECT_AFTER flag, is as follows:
ClutterStage unrealizes: The stage is hidden and unrealize() is called on the stage actor, cascading down to all child actors (including every ClutterText in the scene graph). This must happen before the font renderer is recreated; more on why in the next section.
ClutterContext recreates the font renderer:ClutterPangoRenderer, which holds the GPU-backed glyph cache, is destroyed and recreated with the new CoglContext.
MetaBackend updates the stage: Stage views are rebuilt, and cursor rendering is updated.
ClutterStage realizes: The stage is realized against the freshly rebuilt views and shown again.
One improvement made along the way: Compositor view recreation was previously triggered by a signal emitted when monitors or monitor settings change. With graphics reset recovery requiring the same operation, MetaCompositor would have needed to listen to two sources, along with ordering concerns relative to MetaBackend’s handler, which rebuilds the stage views. Instead, a new MetaRenderer::views-rebuilt signal was added, and emitted at the end of meta_renderer_real_rebuild_views() regardless of what triggered the rebuild. MetaCompositor now listens to that single, unified signal, and the ordering fragility is avoided entirely.
The signal handler ordering for the graphics-reset signal still depends to some extent on GLib connection order, which is not ideal. A more explicit, well-defined ordering mechanism is already in the works.
Recovering the glyph cache
Window content and client-rendered surfaces come back naturally once the context is recreated and stage views are rebuilt, clients re-render their Wayland buffers, and Mutter composites them. But some GPU-tied state lives inside the compositor itself and needs explicit recovery. The most intricate case encountered so far is the glyph cache.
ClutterPangoRenderer maintains a texture atlas of rendered glyphs, built up as text is drawn to the screen. When the GPU context is lost, that atlas is gone. Simply recreating the renderer, as ClutterContext does in step 2 above, creates a fresh, empty one. But there is a subtlety: ClutterText actors internally cache PangoLayout objects, and each layout carries rendering data tied to the old renderer via GObject qdata. Drawing text with a stale layout against the new renderer produces incorrect results or crashes.
The fix required a small chain of additions:
clutter_forget_layout(), a new function in clutter-pango-render, removes the qdata from a given PangoLayout, severing its tie to the old renderer. It verifies that both the renderer and the qdata exist and that the qdata was produced by the current renderer before clearing it.
ClutterText.unrealize(), a new virtual method implementation, calls clutter_forget_layout() on each of ClutterText‘s internally cached layouts when the actor is unrealized.
When ClutterStage unrealizes (step 1), the unrealize cascade reaches every ClutterText actor in the scene graph, clearing stale layout data across the board.
This is precisely why the stage must unrealize before the font renderer is recreated. ClutterText‘s unrealize() calls clutter_forget_layout(), which requires the old renderer to still be alive to destroy the layout’s qdata. If the renderer were already replaced, it would be impossible to correctly destroy the data. The stage is then re-realized in step 4, after the new renderer exists and stage views have been rebuilt, allowing text to render cleanly from a fresh cache.
Where things stand
As the recording shows, the compositor survives a GPU reset, and the session remains usable: windows update correctly, input is responsive, and the session doesn’t crash or freeze. There are two notable gaps, though.
First, framebuffer recreation isn’t automatic yet. After recovery, the display stays dark until something triggers the creation of a new framebuffer; in the recording, I do this manually by maximizing the active window via a keyboard shortcut. Without that nudge, stage views are rebuilt, but nothing causes a fresh framebuffer to actually be allocated, so the screen just stays black. Making this automatic is one of the next things to sort out.
Second, once the display is back, the desktop background renders with incorrect or garbled textures. MetaBackgroundImage and MetaBackground hold references to GPU textures (primarily the background image loaded from disk), and MetaBackgroundContent defines GLSL shaders, all of which are invalidated by the reset. Recovering them requires updating these objects to re-upload their GPU-side resources after the reset.
There are also residual GL errors after recovery that need investigation, and the signal handler ordering situation deserves a more deterministic solution.
What’s next
Signal handler ordering: replacing the implicit connection order dependency with an explicit, documented mechanism.
Automatic framebuffer recreation: removing the dependency on a manual trigger (like maximizing a window) for the display to actually come back after recovery.
Background texture recovery: getting MetaBackground and its counterparts to listen to the graphics reset signal and reload their GPU-side resources.
Auditing remaining GPU-tied resources: ensuring nothing else in the compositor holds stale references after recovery.
MR review and upstream integration: the current implementation lives on my fork and is primarily only reviewed by my mentors; as the approach stabilises, it will be proposed for upstream review.
Thanks
A huge thank you to my mentors Jonas Ådahl, Robert Mader, and Carlos Garnacho for their incredible guidance since the beginning. I’d also like to thank Bilal Elmoussaoui for the valuable review comments on my merge request. On to what’s next!
When you log into a service you’re given an authentication token. Each
further request to the site includes that token, allowing the server to
figure out who you are and ensuring that you have access to your
data. Depending on site policy, this token may either be stored in memory
(and so vanish if you restart your browser) or disk. The token is the proof
of your identity. As far as the site is concerned, anyone with your token is
you. These tokens may be traditional browser cookies, but they may also be
stored in either site local storage or (if you’re not using a browser) in
some other storage location.
In recent years we’ve seen infostealer malware (like
LummaC2)
gain the ability to exfiltrate user tokens, allowing attackers to gain
access to the user’s data without needing to retain access to the user’s
machine. This attack is viable even if the site has strong MFA requirements,
so passkeys don’t help. Encrypting the tokens on disk doesn’t prevent the
malware from scraping them out of the browser’s RAM or obtaining whatever
key is used to encrypt them. This feels like a pretty hard problem to solve.
But that hasn’t stopped people from trying! Dirk Balfanz wrote an IETF draft
describing a mechanism for using self-signed certificates for TLS
authentication. This
uses the mutual
authentication
feature of the TLS protocol that requires both sides prove their identity to
each other. In regular TLS, the remote site presents a signed certificate
that tells you who it is. When performing mutual authentication, you then
present a certificate to the remote site telling it who you are. These
client certificates are largely unused outside enterprise environments
because they’re a huge pain to deploy. It’s not so much that this has
sharp edges, it’s that it’s entirely made of sharp edges. Managing
certificate deployment to your devices is hard. Browsers get confused if the
certificates change under them. You have one certificate and it lives
forever, so sites you present it to can track your identity. Users are
prompted to choose a certificate to authenticate with, and if they pick the
wrong one everything breaks and is hard to recover. I’ve deployed this and I
did not have a good time.
But Balfanz’s idea was simple. Rather than require certificates to be
deployed, browsers would simply generate a certificate on the fly. The goal
wasn’t to prove the device or user’s identity in any global way - but it
would associate a TLS session with a specific certificate. You could then,
for example, include a hash of the certificate in the cookie, and if someone
tried to use that cookie without presenting that certificate then the cookie
could be rejected. If the browser used a hardware-backed private key for the
certificate then it would be impossible for an attacker to steal it. Sure,
you could still steal cookies, but you wouldn’t be able to use them.
This was written almost 15 years ago, and seems simple, elegant, and
functional. It didn’t happen. Part of the reason for that is that, well, it
wasn’t quite so simple. One problem was privacy related. Cookies are only
sent after the TLS session is established, so anyone monitoring the network
doesn’t know anything about the user identity. A naive implementation of
this approach would have meant the client certificate being sent before
session establishment, and now user identity can be tracked (no longer an
issue if this was implemented on top of TLS 1.3, but this was a log time
ago). This was avoided by reordering the client handshake, but that meant
having to modify the TLS specification and implementations would have to be
updated to support this. Another was that figuring out the granularity of
the certificates was difficult. You’d want to use different certificates for
every site to avoid them effectively becoming tracking cookies, but you need
to provide the certificate before cookies are set, and you don’t know what
origin the site is going to set in its cookies. If you generate a
certificate for a.example.com and a different one for b.example.com, and
a.example.com sets a cookie for *.example.com and includes the certificate
you used for a.example.com, that cookie isn’t going to work on b.example.com
and things are broken. This meant supporting it wasn’t as straightforward as
it seemed - you’d need to ensure that your cookie scope was compatible with
the certificate scope. You could probably make this work well enough by
aligning it with the Public Suffix List, but
there was still some risk of expectations not being aligned.
And, perhaps most importantly, TLS session
resumption (replaced by
pre-shared keys in
TLS 1.3) somewhat defeats the purpose of the exercise - clients store state
that allows them to re-establish a TLS connection without performing
certificate exchange (this reduces overhead if a connection gets interrupted
or you switch to a new network or anything along those lines), and anyone in
a position to steal cookies could steal that state as well.
The followup attempt was channel
IDs.
This simplified the implementation somewhat - rather than certificates, a
raw public key would be sent, along with proof of possession of the private
key in the form of a signature over a portion of the TLS handshake. This was
required even in the event of session resumption, which avoided having to
worry about theft of session secrets. The timing of the exchange was after
the encrypted session had been established, so user identity couldn’t be
leaked that way either. Cookies could then be bound to this
identifier. Unfortunately it didn’t really deal with the problem of scoping
keys in a way that would match cookie requirements, and the spec suggests
that the right way of handling this is to scope keys to TLDs, which would
enable user tracking across sites (Chrome’s implementation apparently
restricted it to eTLD+1, which would match the third party cookie policy and
avoid the tracking risk).
Chrome added support for this, but it was removed in early
2018. The
discussion of some of the pain points in that message is interesting,
explicitly calling out problems with connection coalescing across domains
and the incompatibility with zero-RTT TLS1.3. The overall consensus at the
time seems to be that trying to solve this entirely at the TLS layer has too
many rough edges, and a different approach should be taken.
And so almost 7 years after the initial draft for origin bound certificates,
we come to token
binding. This ended up being
a rather more complex endeavour, covering 3 different RFCs describing how it
impacts TLS, how to incorporate it into HTTP, and how to manage all the
various parties involved in the process. The short version is that it’s
pretty similar to channel ID, except that there’s also a documented
mechanism for allowing tokens to be bound to one party and consumed by
another, avoiding any need for widely scoped keys. Token binding effectively
solved all the issues in the original proposal, but at the cost of somewhat
more complexity.
The RFC was finalised in October 2018. Chrome removed its (incomplete,
draft) support for token binding in November 2018. Edge carried support
until late 2024. Despite getting all the way through the RFC process, it’s
functionally dead.
The process up until this point had been largely initiated by Google, with
Microsoft contributing significantly to the token binding standards. The
work had been focused on identifying a generic solution to the problem
rather than tying it to any specific authentication flow. The next step was
in a different direction - rather than trying to fix this for the entire
internet, how about we try to fix it for OAuth?
RFC 8705 is titled “OAuth
2.0 Mutual-TLS Client Authentication and Certificate-Bound Access
Tokens”. This is basically the 2011 approach, but (a) with an explicit
definition of how the certificate should be incorporated into issued auth
cookies, and (b) with a proviso that well uh if you’re going to use tokens
issued by your IdP to authenticate to someone else then well you’re going to
need to use the same cert for both. This is probably fine for the
company-owned-laptop case where you’re actually fine with multiple sites
being able to tie identities together (that’s kind of the point here!), and
also works for “I am using an app and not a browser”, but doesn’t work for
more generic scenarios. It also doesn’t seem to take the session resumption
case into account at all? Support for RFC8705 seems poor, as far as I can
tell of the big players only Auth0 implements it. In theory it works fine
with self-signed client certs but in reality that’s going to be almost as
difficult to support across multiple platforms as just issuing proper client
certs in the first place, so deployment is going to be kind of a pain. But
the good news is it doesn’t rely on any TLS extensions or custom browser
behaviour, so at the client side it works fine with any browser.
Which brings us on to RFC
9449, “Demonstrating Proof
of Possession”. This goes even further than RFC8705 in terms of reducing the
burden of deployment - it works fine with existing browsers, and it
doesn’t even require any certs. The client generates a keypair and provides
the pubkey when requesting the cookie. The cookie contains the pubkey. Every
request to the service now provides the cookie with the pubkey and also
provides a signature over the URI and HTTP method. If the signature matches
the pubkey in the token then clearly the signature came from the machine the
token was issued to, and everything is good.
This does come with some downsides, though. The first is that it uses
browser interfaces to generate the keys (typically
crypto.subtle.generatekey())
and as far as I can tell there are no browsers that guarantee that that key
is going to be generated in hardware even if it’s marked non-exportable, so
anyone able to steal the cookies can also steal the keys. The second is that
the signature only covers the URI and HTTP method, and not the message
content or any other headers, so anyone able to exfiltrate a valid signature
can replay it against the same URI with different message content. The
recommended way to handle this is to reject any signatures that weren’t
generated within the last few seconds, which is a wonderful additional way
to allow clock skew to give you a Bad Day. And the third is that every
single request has to be separately signed, which is not intrinsically a
problem because computers are fast and have multiple cores, but if you’re
trying to solve the first problem by sticking the key in a TPM then you’re
dealing with something that’s slow and single threaded and that’s maybe
acceptable if you’re using client certificates (because there’s going to be
one signature per session and you can use the same session for multiple
requests) but probably not if you’re dealing with a user opening a browser
that restores previous tabs and each of those is a webapp that fires off 100
requests in parallel.
In case it wasn’t clear, I don’t like DPoP. It doesn’t feel like it actually
solves the underlying problem that we see in the real world (malware running
in a context where if it can grab the tokens it can grab the keys), it adds
a massive amount of overhead, and it has baked in replay vulnerabilities. I
don’t know why it exists and I’m incredibly suspicious of vendors telling me
that it fixes my problems, because if they’re telling me that then I’m going
to end up assuming that they either don’t understand my problems or they
don’t understand their technology, and neither of those is good.
Still. Then we get to the thing that prompted me to write this - Chrome’s
announcement that they had launched device-bound session
credentials. This
is interesting because it’s a Chrome feature that’s explicitly intended to
counter on-device malware, which was one of the things that was out of scope
in 2018 when token binding was being removed. Since this is entire web level
it doesn’t have to be an RFC, and so is instead defined by
W3C. I’m going to handwave all the
complexity and say that it’s basically a way to register a public key when a
cookie is issued, and then prove possession of the private key when it’s
time to renew the cookie. By making the cookies shortlived and having
support for rotating them in the background, user impact is basically zero
and while it’s still possible for an attacker to exfiltrate and use a cookie
they’ll only be able to do so for a short window before it needs to be
refreshed - something the attacker can’t do, since they don’t have the
private key. This avoids the DPoP overhead because you only need to do
signing once per cookie per cookie lifetime, and not on every single
request. I don’t like this due to the window where exfiltrated tokens can
be used, but it feels like a strict improvement over the status quo. An
extension called device-bound session credentials for
enterprise
allows pre-enrollment of device keys, so even though the actual runtime DBCE
flow doesn’t involve certificates, certificates can be used for device
registration in enterprise environments and you can make sure that auth
cookies only go to trusted devices. Unfortunately this is Chrome-only, and
so we’re going to need to wait for it to be backported to all the random app
frameworks for it to have widespread support on mobile or for almost
everyone’s desktop app that’s actually three websites in an Electron
wrapper. Mozilla’s current
position
is that they’re not in favour of it, so I guess we’ll see where Safari lands
in terms of broad uptake.
The last thing on my list is another client cert/OAuth
binding,
this one still in draft state at the time of writing. This one is aimed
primarily at the use of agent-driven tooling, where you have something
running in the background using a whole bunch of tools that are each acting
on your behalf. Authenticating to all of them separately isn’t a fun time,
but giving broadly scoped access tokens to a non-deterministic agent and
trusting that it’ll never post them somewhere public also isn’t a fun
time. The key distinction between it and RFC8705 is that it’s aimed at
connections rather than sessions, which avoids the worries about session
resumption. This is done with TLS
Exporters, which in TLS 1.3
should be unique to the connection even over session resumption (TLS 1.2 may
reuse some of the same key material for exporters over session resumption,
so it’s recommended to enforce 1.3 for this). By providing a new signature
alongside the cookie on every new connection, the client proves that it
still has access to the private key. This is a very new spec and I haven’t
had much time to work through it yet, but my naive understanding is that
unlike RFC8705 this would require some additional client support to be able
to regenerate the client signature on every TLS reconnection.
This doesn’t avoid all the problems that RFC8705 has, including how to scope
certificates. For the agentic use case that probably doesn’t matter - all
these tools are acting on behalf of the same user, it’s fine if all the
sites involved know they’re the same user. But it doesn’t solve the general
purpose user use case, and right now DBSC seems like the best we have there.
But. Part of me still wonders whether Dirk
Balfanz’s
approach was the right one. Yes, there’s risk associated with TLS session
resumption, but in the worst case you could just switch that off for high
risk setups. The cookie scope argument is real, and also in cases where it
could violate privacy the site owner could already choose to broaden their
cookie scope and violate your privacy, and in cases where it breaks things
you could just not make use of it. The other problems are largely fixed by
TLS 1.3, and then we’re just left with “Browsers handle client certificates
badly” to which my answer is “Yes, and we should fix that anyway”.
Despite having a pretty good answer to this solution over a decade ago, the
closest we have to actual deployment is something that offers strictly worse
security guarantees. And tokens keep getting stolen, and compromises keep
occurring, and for the most part people shrug and get on with things.
Hello GNOME, This is a progress report on the Pitivi Timeline Ruler Rust rewrite.
Progress
We are rewriting the Pitivi Ruler in Rust using a modern GtkSnapshot rendering pipeline to improve performance and memory safety. At its current stage the ruler is being constructed as a standalone widget in a personal repository that can be found here:
The widget is drawing well and a lot of the initial bugs have been ironed out.
A major structural change that has been made after mentor feedback was to pull state orchestration out of the widget itself, and keep more of the logic on the app side. The goal is a "dumb widget, smart app" framework, where the ruler acts as a stateless viewport. The app (or sandbox example) provides the logic for how to handle gestures and what to do when the user interacts with the widget. One example of this is that project_duration was removed as a property entirely, and logic around bounds is now handled entirely on the app side. This allows the widget to be used in a variety of contexts, and allows the app to handle bounds in whatever way is appropriate for the context.
Beyond the pivot on structure, some key systems-level refinements were made:
Property types we refactored heavily as this moved past the rough prototype stage. zoom_level received a rename to ns_per_pixel to better reflect what the property actually represents. Many properties dealing with pixels were changed to unsigned integers, which allowed me to delete out some negative checks.
The project does now include a rough doc string and comment draft for the widget, which will be fleshed out more as the widget matures and more of the public API is finalized.
Cache clearing was added to set_ns_per_pixel to prevent modulo math escapes during purging of cached layouts when users change the zoom level.
Next Steps
The major milestone ahead is the implementation of a custom gtk::LayoutManager to handle the layout of children widgets.
Once the PitiviTimelineLayoutManager is implemented, the playhead rendering will be moved out of the ruler's snapshot pipeline and into the layout manager as a distinct child widget. This will allow Pitivi to easily inject custom markers, loop-brackets, and multiple playheads without modifying the underlying ruler engine.
I am currently studying Marc-André Lureau's rdw (Remote Desktop Widget) repository as a guide on how to make this update.
GNOME developers have long used G_GNUC_CONST, which expands to __attribute__((const)), to annotate GObject _get_type() functions, despite knowing that it is incorrect to do so. const functions by definition have no side effects, but _get_type() functions actually have a side effect the first time the function is called: they initialize the type. Why apply an incorrect annotation to these functions? Because it makes the code faster.
Although this was long known to be incorrect, it worked fine in practice… until now. Regrettably, Sam James has discovered that GCC 16 may optimize away the type initialization, resulting in crashes. This is our fault for providing the compiler with wrong information about our code, so it’s time to audit your use of const attributes to remove them from _get_type() functions. Most GNOME programs use these attributes only for _get_type() functions, but if you use it in more places, then check to make sure those functions are actually const, as defined by the GCC documentation.
Sadly, there is no suitable replacement attribute for _get_type() functions. Two decades ago, Behdad requested a new idempotent attribute for expressing the desired semantics, but nobody has implemented it.
File under: brief half-year catch-ups, me not remembering when I last updated the back-end of this blog
I’m writing this from a terrible AirBnB in Reading, having just wrapped up a four-day visit to my old Typography & Graphic Communication alma mater and happy to have an excuse to put off re-packing. I’ve been fortunate in the first six months of this year to have time to participate in a number of in-person conferences after a few years of not being able to travel, and when I was looking back at the calendar I noticed that these events have been evenly split between FOSS events and type-related events, so I decided it’s worth jotting down a few of the thoughts that presented themselves before they fade away entirely. Here’s a recap:
SCALE: The Southern California Linux Expo (which, for the record, I refuse to bacronymize in a mixed-case form, so don’t at me about the capital A). I’ve been a regular for yikes years at this point, and have helped coordinate the “libre graphics track” for the past several, but this time I actually had to present a workshop as part of that. It was on the subject of learning Scribus if you’re coming from the world of LibreOffice / Microsoft Word / Google Docs / Etc. Turns out that’s an ambitious subject, scope-wise, and we didn’t get through everything I wanted to.
But for me, that highlights the fact that shifting from one Do Real Work application to another is always a monumental effort. Sure, you can fire up GIMP and do some cropping of images in a matter of minutes. But you can’t drop a full production workflow without a lot of spare time, because every individual sub-task now involves a different order of operations (or different operations), a different cycle of tool-switching, and a different set of cross-checks and QA. I don’t think we give this problem enough attention, especially when the well-meaningers on social media (and yeah, that includes Mastodon, as fully as whatever platform you don’t like) entice people to give it a try like it’s no big thing.
It also reiterated for me how important document templates are. Those are fairly forgettable 99% of the time, but what ships in the template choosers of LibreOffice, WhateverOfficeOnline, and in more specialist apps is what people end up using when they need to get things done. The typography in most FOSS templates is pretty awful: the fonts are weak, the hierarchies are non-existent, the alignments are haphazard, and the optical balance is even more non-existent than the hierarchies. I suspect that this can only be improved with a long, slow, many-person grind. I don’t know where to start.
WAVE and ATypI: Both of these are type-related or type-adjacent events, so I don’t have much that feels relevant to say about them here. WAVE is quite specialized, since it focuses on human writing: just as many of the presenters are linguists as anything else, and the type people made a stronger showing this year than they did in the original event a couple of years back but aren’t the majority. It is genuinely a wake-up call to sit down and learn about a written language that does not operate in the way that your own does, and to hear exactly how many people use it every day (as well as to see photos to remind you that all of this happens in the present, when it’s incredibly easy to write off those concerns as belonging to an earlier era in printing and just presume that Computers Fixed All That. Or that OpenType and Unicode did. Or that FOSS did.).
I do think, however, that most of the FOSS projects I’m involved with keep a stout set of blinders on about non-majority language systems and scripts, and that that’s deeply problematic. Indeed, it was not long ago that I mentioned IRL that GNOME could do a valuable bit of good for the global user community by finding and supporting scripts other than Latin/Greek/Cyrillic — in contrast to today, where the attitude is “oh, those users will figure it out for themselves like they always do aren’t they great over there” and/or “Noto Fixed All That.” It’s not hard to say that the next release of your project will also support, say, Arabic, and to at the very least be deliberate about bringing people into the room to find and test the fonts you need to determine if things are working and look good. Yes, you do have to do actual tests. Yes, I mean you.
ATypI, in contrast, is very much a “type production” event. For me, this year the bit that stood out was behind-the-scenes stuff that eeped out around the seams and got more widely discussed. Like, there was evidently initial interest from some on the local organizing side that there would be a verrrry small list of presenters: less than two dozen, total, for 3–4 days (depending on how you count workshops and exhibits). Far less than two dozen. There are two big gotchas there. First, you have to contend with gatekeeping. All of the well-known people are likely to be the ones with The Exciting Announcement to announce and, in theory, they’re a big part of the draw. But that keeps all the new community members out. Second, it crashes the economic viability of attending the event. The locale this time was Stanford, which (despite being perhaps the world’s only Junior University, look it up) is outrageously expensive, even if you already live outrageously in nearby northern California. And any time people can’t justify the cost of travel, yes you’re gatekeeping again (particularly of the hallway track), but you’re also twisting the dial on your conference further from “I Should Go” over to “Going Is Just Paying Money To Be In The Audience Of A YouTube Video That I Can Watch Any Other Time” … which is a hard dial to reverse.
LGM: The Libre Graphics Meeting seems to be back on its feet and in good form after several post-pandemic years of bumping into things. Massive props. I had a lot of side-project stuff I brought along in disorganized form, although I attended every session. I also quasi-roundtabled a session to talk about how the now defunct “Planet LibreGraphics”, may it rest unpeacefully, used to be the clear answer to the perpetual question of “how do we maintain momentum and connection the rest of the year?”
But whereas the old Planet site was a garden variety class-M aggregator of individual blogs’ RSS or Atom feeds, I’m of the unprofessional opinion that a true community aggregator today has to account for different types of inputs and outputs and user modes (sideputs?). E.g., many projects don’t announce new releases on their project blog anymore; they tag a release on GitHub. That’s a different input. A lot of people don’t post long-form content anymore, but do a lot of microblogging. That might suggest having an ActivityPub output … but it would be a bot, and it would incur a TON of overhead and put scores of messages out all day long, which you definitely couldn’t use on the traditional RSS output. So you probably need to handle those differently, maybe batching the Mastodon bits into a once-per-day blog output?
Ultimately, I’m not sure; there are a lot of these details. We’re way out in the high-cosmic-ray environment of the trans-neptunians here, or some other metaphor. Ping me if you find the question interesting, because I want to talk a lot more about it.
LAS: It was my first time going to the Linux Application Summit, as the kids call it these days, so I have more thoughts to get down about that one. For starters, it wasn’t what I expected, because I expected there to be more people there who develop Linux applications. I covered a lot of growth of post–CD-delivered-and-RPM/Apt-updated packaging efforts when I was toiling as a not-so-young FOSS journalist, so I do think I have the right grounding in systems like Snap, Flatpak, FlatHub, AppKit, immutable-image OS approaches and other user-code–confinement technical building blocks. Except Kubernetes; I never cared about that and never will.
Anyway, all of that stuff (hand-waving) is very much where LAS takes place. It’s really good to see that there are people from multiple application ecosystems talking about how they handle the current set of unsolved problems. Selfishly, one of the sessions that stood out most to me was Carlos Garnacho’s talk about the data-search layer that he’s been working on. The gist there is that it’s for searching local data … which you might think you can already do, but you’d be wrong. You can sort of do filesystem-level text searching, but that doesn’t handle complex stuff, and it really, really doesn’t let you handle per-application searching well. I’ve got a keen interest in what people do with their “big data exports” — we FOSS people like to look down our noses at the public and tell them that they should take all of their content out of The Bad Services and walk into the sunlight. But there’s not anything they can do with it when they get here (or there, depending on how you feel), and they’re the ones holding the bag. The TinySparql and LocalSearch stuff, I think, holds the potential to improve on that in a big way.
I was also quite interested to learn more about how the KDE ecosystem does its builds. I don’t do … builds, at least not in the sense that KDE and GNOME do (nor, who else, who else … Enlightenment, maybe?). But I have been forced against my will to get up to speed on some things like GitHub Actions, and the session about KDE’s build architecture did make me want to go back and re-examine some stuff I’ve built. That being the other sense of “build.” I was also very interested in Evangelos Paterakis’s talk about the gritty realities of picking up an abandoned project, reviving it in fork-form, and getting hit with the consequences of that decision from both upstream and downstream.
For most people, what matters in these sort of pseudoplumbing projects in what’s going to be accessible in end-user applications whenever they land on the next platform releases. That’s why I thought I might encounter app developers at LAS. Instead, much of the session content was about enhancing the the plumbing layer themselves: what’s going on with portals, how sandbox/confinement techniques either fail-open or fail-closed, and where the confined-application model is still leaking.
I suggest checking out Sebastien Wick’s talk about the portal situation if nothing else; the slides are available now, even if the video is not. Whenever the videos go up, I also suggest that everyone watches the session about forking a defunct project … not because it’s something everyone should do, although let’s face it, projects appear and fizzle all the time. But mainly because the social aspects of how a revived fork does or doesn’t catch on are things the FOSS community doesn’t say out loud. Not bad or shameful things, just sharp corners.
All that said, I think that what really needs to happen is for application developers to actually go to this event. I know you think you don’t need to. But the platform layer is another one of those things about which you can easily say “Didn’t Somebody Already Handle That?” and be incorrect for a long period of time before it bites you. Moreover, every time I’ve ever asked the developer of a Mac or Windows desktop app what they know about developing Linux apps, they tell me a story about running into giant potholes, missing documentation, and mismatched API expectations. The presence of Linux app developers at a plumbing-layer conference will not instantly fix that, but I do know that a lot of those Linux developers hit the same roadblocks.
LGM made a massive improvement to the ecosystem of creative-arts apps in FOSS specifically because it involved getting users, app developers, and subsystem developers into a single space. That’s not a magic trick, and the general Linux app universe would benefit from repeating the technique.
Grapholinguistics in the 21st century, also known as /gĘafematik/: This is the one I just came from, and I don’t quite have it all simmered from ingredients into stew just yet. Apart from being hosted in an initially un-airconditioned spot at the university in the hottest UK week since 1666, I don’t think I have any complaints. I introduced speakers and acted as moderator for Q&A blocks, and apart from that I visited with most but not all of the rest of the quantitative type-research clique. You know where to find us.
One takeaway, perhaps, that will be generally useful is that I spent much of the inter-session time when I was on moderator duty trying to gauge the level of nervousness of the upcoming speaker and attempting to defuse it. I don’t know how successful that actually was, but I do think there were sessions elsewhere where it might have made a difference. I don’t know; perhaps that’s projecting.
Anyway, before the Internet runs out of bits, I should wrap up. I do need to be sure to express my appreciation to the GNOME Foundation, who chipped in with some travel expense assistance for LAS, as well as to my friend and mentor-in-a-few-very,-very-limited-capacities-I-can’t-emphasize-that-part-enough Sri Ramkrishna for pinging me about it and then reminding me. I’m definitely glad I went.
At the moment, I’m halfway through reconfiguring the blog site here into static format (fighting Unicode support in the old platform), so don’t count on commenting to work. If you want to reply to anything I said here, try me on Mastodon.
I have overhauled Bazaar’s curated page. Vendors, such as distributions, can now make use of several widget types to showcase the apps they want to promote to their users.
One of these widgets displays articles, which can be used to recommend apps or share general news about the OS in a place where users will naturally discover them.
(The data shown is only for illustrative purposes.)
I published last week the first release of EdiTidE.
It’s a simple source-code editor, something between the GNOME Text Editor
and GNOME Builder. Think of it as an alternative to Notepad++ in terms of features.
It works fully sandboxed, and is quite convenient to quickly open a project and browse the code in.
It has a bunch of settings for customization (like for replacing the menubar by a hamburger button, to make it more GNOME-ish), and can be enhanced with extensions (in Python).
Whisp Update: Smart Text Expansions, 4k Downloads, & Donations!
Whisp just crossed 4,000 downloads on Flathub! Thank you all for the incredible support. Donations are officially live! If Whisp helps your workflow, you can now support its solo student development via Ko-fi or GitHub Sponsors on the website.
In v1.3.4, we’ve also added a major new feature to remove friction from your workflow: Smart Text Expansions.
Typing :: anywhere in a note now opens a lightning-fast, completely keyboard-navigable GTK popover to instantly insert dynamic data:
::today / ::date(5) for dynamically calculated dates.
::roll(d20) for D&D dice rolls.
::random(str, 20) for instant secure passwords or placeholder text.
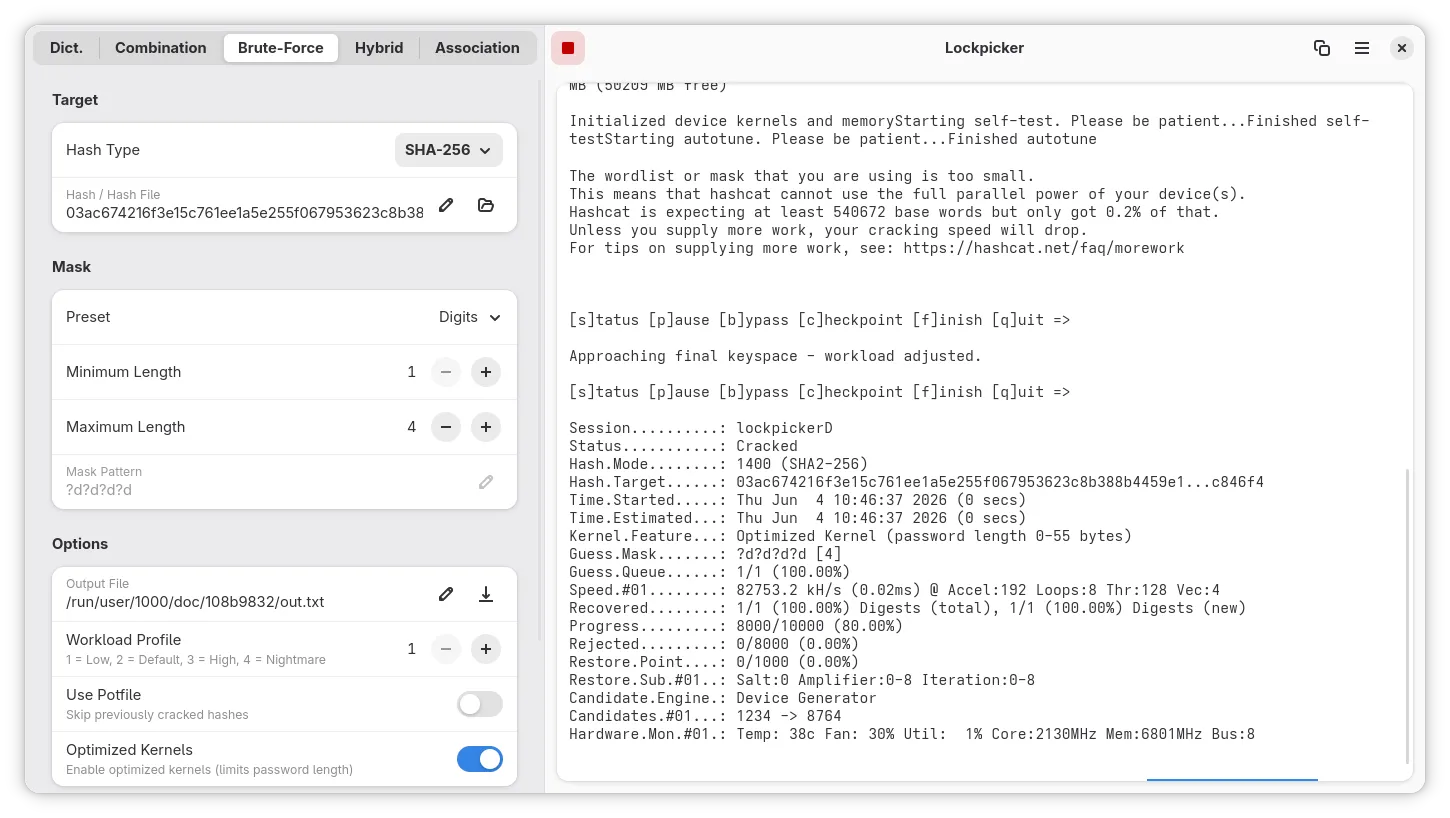
This week I’ve released several updates to Lockpicker, a new tool to recover passwords from their hash. The most obvious change is that the console-output has been replaced by friendly widgets, giving a much more convenient overview. The status overview also spots a progress bar to see how many candidates have been tested. And the ordering of the sidebar should be more intuitive. The logo has also been updated to look a bit more proper for now.
Lockpicker now also has support for sessions. You can pause a session, or run multiple in parallel. Sessions persist over reboots, so you can pick up any time it’s convenient. Finally word lists and rules can now imported into the application, and be chosen from a dropdown menu.
This is the first release since RustConn turned one, and it landed just two weeks after 0.16. Despite the long feature list, the goal hasn’t changed: RustConn is still a simple address book and orchestration layer over your connections, nothing more.
The headline this cycle is Workspaces. With a dozen sessions open across split panes, you can now save the whole set as a named workspace and reopen it in one click - every connection, tab order, split layout, and tab group restored. Reboot the laptop, come back, and your working set is exactly where you left it. No more leaning on clusters and re-clicking reconnect.
A few other highlights, mostly user requests:
Simple Sync - opt-in bidirectional sync of connections, groups, templates, and snippets across devices. Passwords stay in each device’s keyring, never in the sync file.
Native PKCS#11 / YubiKey SSH auth - hardware-token keys offered directly, no SSH-agent workaround, works through jump hosts too.
Built-in port knocking and fwknop SPA - open a firewall before connecting, pure-Rust, no external CLI.
Gitte, a simple Git client for GNOME built with GTK4, libadwaita and Relm4, just got its 0.8.0 release! 🎉
The headline feature this time is cherry-picking: you can now grab one or more commits straight from the commit log and apply them onto your current branch. Diffs also learned to handle the awkward cases gracefully. Binary files and overly large diffs are now clearly marked as such across all diff views, and there’s a new “filtered files” option that lets you configure paths which are treated like binary files and kept out of diffs. In the working copy view you can filter what’s shown to new, tracked or all files.
You also get more space when you need it: you can maximize the diff view with Ctrl+M, and in the commit graph that shortcut cycles between maximizing the graph, the diff and the normal layout.
A few new things can now be configured per repository: you can set merge-/pull-request and issue URLs manually for each one, and pick a default location for new and cloned repositories (thanks to René Fouquet!).
On the UI side, the revert dialog and the commit detail box got an overhaul.
And of course there’s the usual pile of fixes: bad SSH-signed commits are now shown as bad instead of “key unavailable”, commit messages now conform to the Git specification, and signature verification finally works under Flatpak, where the verification temp file is now written to a path that’s also reachable from the host.
Under the hood there’s a fresh Chinese (zh_CN) translation (thanks to Dawnchan030920), new just / bacon developer commands including recipes to build and run as a Flatpak (thanks to Bahrom Magdiyev), and the Nix flake can now build and run Gitte directly with nix build / nix run (thanks to bitSheriff).
New GirCore C# bindings got released in version 0.8.0. The most prominent feature is GTK-Template support which required some breaking changes. Please read the release announcement for details. Further changes included support for GNOME SDK 50, several under the hood fixes and improvements to make working with GirCore easier.
Thanks to user submissions, this release includes new and updated translations and improved accessibility. There are also some subtle bug fixes alongside some more noticeable new features.
Bouncer now uses more modern Adwaita widgets throughout, replacing basic labels and buttons for a more polished look and feel. The dashboard has also been redesigned as a tabbed interface, with a new Networks tab where you can change the firewall zone for a saved network or make Bouncer’s forget it altogether.
On the road a lot of frequently use VPNs? Show External IP extension does what it says and displays your external IP in the Toolbar, including Country flag. It sends a system notification if your IP has changed. Shows also IP history with Export and an image of the approximate location.
This extension is handy for those who work at different locations or with different VPNs to quickly see your public IP and country.
Medialine is a GNOME Shell extension that shows your currently playing media right in the top bar, in a minimal and elegant way.
It detects any MPRIS-compatible player (Spotify, Chrome and even PWAs) and displays the track inline in the panel. Click the indicator to open a rich popup with album art, a live seekable progress bar, and full playback controls — shuffle, previous, play/pause, next, and repeat. Supports multiple playing media in a compact view.
The highlight is basically the support for PWA, it properly recognises the PWA icons and opens the correct window when clicked. Also has dynamic background color for the pop-up, based on the album art of the playing media.
I submitted talk proposals about Pystd, the from-scratch written standard library for C++ (custom design, not a implementation of the ISO specification) to a bunch of conferences. Unfortunately all of them were rejected, so it's blog posting time.
A controversial opinion
Pretty much everybody agrees that compiling C++ is slow, but I personally feel that it is intolerably slow. Other people might disagree, and that is fine, but let's look at some numbers.
Compiling a helloworld executable in C takes approximately 0.02 seconds. Compiling a C++ exe that does the same thing using #include<print> takes a second if optimizations are disabled and up to 2.3 seconds with them enabled. This is approximately a 100x slowdown. I'm using a Ryzen 7 3700X processor, so not the latest and greatest but not too shabby either. I have talked about this slowdown with some people in person and weirdly often their answers have been "that's not a problem, two seconds is insignificant". Even if you accepted this (which personally I don't) the big problem comes from scaling because the slowdown factor is approximately linear. Let's assume that in a less extreme case the slowdown was only 20x instead of 100x. In this case a program that should be done in 0.1 seconds takes 2 seconds, and therefore a program that should compile in one minute would take on the order of 20 minutes to compile.
Why is compilation so slow?
C++ is actually very fast to compile, the slowdowns come mostly from the way the standard library is implemented. This is actually fairly easy to test yourself by running the following shell snippet.
The -E flag tells the compiler to stop after preprocessing. The output is the source code that is fed to the compiler proper. Instead we pass it to wc and find out that merely including vector expands out to 29 000 lines of code. The number is not directly comparable to "human written code", but still, almost 30k lines of code just to get a growable array of elements seems a bit much. And vector is actually one of the lighter headers. Memory is 55 thousand lines (especially bad, since 99% of the time people just want unique_ptr), print is 65 thousand lines and filesystem is 80 thousand lines.
The unfortunate reality is that if you include even a single standard library header, your compile times tank and there's nothing you can do about it.
Just say no
Pystd was originally just a project for me to implement low level primitives (hash maps etc) for scratch for the fun of it. Pretty quickly I came to the three design priorities:
Compilation time
Simplicity of implementation
Performance
I'm not aware of an existing standard library where build time minimization would have been a design priority. Those that are fast, like the standard libraries of C and Go, seem to mostly follow from the simplicity of their respective languages.
At the time of writing building Pystd and all tests from scratch using a single core takes 4 seconds. This consists of 45 individual processes (mostly compiles, a few links). Enabling optimizations balloons the build time to 9 seconds. Using all 16 cores brings it down to 1.9 seconds.
What we have thus far
If we ignore test code, Pystd has 6500 lines of headers and 5600 lines of source in total. Even adding these two together yields a line count of roughly one third of std::vector's (preprocessed) implementation. Functionality provided by Pystd includes:
sort (approximately as fast as stdlibc++), stable_sort (faster than stdlibc++)
Random selection of things in the ISO algorithm header
Optional, expected, variant, unique_ptr
Functionality roughly equivalent to Python modules argparse, pathlib (including the ** operator), regular expressions (using pcre) and tempfile
Note that not all of these are "complete" as it were. Typically they only contain the most commonly used subset of functionality. That might be a fairly small.
Performance
There is an earlier blog post about the performance. The numbers for converting the CapyPDF library are as follows:
Compile times dropped ~80%
Unstripped binary size reduced by ~75%
Stripped binary size reduced by ~30%
Runtime performance became ~25% faster (yes, faster, not slower)
Regression can be prevented
Two typical issues people raise when hearing something needs to be "fast to compile" are the following:
What even is "fast"? It is highly subjective thing that depends on each person and the computer they are using.
Even if something is fast now, it can not remain fast. New functionality gets added all the time, so the code is destined to become ever slower and eventually it is just as slow as the default standard library.
The boring solution to both of these issues is the same: a predefined time budget. Pystd has a requirement that compiling a source file that includes any single public header must take at most 0.15 seconds. This limit was originally 0.1 seconds and it worked perfectly with GCC, but Clang's process startup time is longer than that. The test script that validates the performance is here. It must pass even on a Raspberry Pi.
Interestingly the tester script was not originally single-threaded. I parallelised it only because it was the single slowest part of Pystd's compile-test cycle taking over a second.
This is the requirement that all new functionality in Pystd must meet. If the code you want to add compiles too slow then either you rewrite the whole package to compile faster or you submit a patch to the upstream compiler to make it run faster.
In the weeks leading up to that release (and since then) I have posted
a series of serieses of posts to Mastodon about key new features in
this release, under the
#systemd261
hash tag. In case you aren't using Mastodon, but would like to
read up, here's a list of all 27 posts:
I intend to do a similar series of serieses of posts for the next
systemd release (v262), hence if you haven't left tech Twitter for
Mastodon yet, now is the opportunity. My series for v262 will begin in
a few weeks most likely, under the
#systemd262
hash tag.
When I started contributing to Flatseal through the Igalia Coding Experience program, I expected to spend most of my time writing code.
I quickly discovered that I was wrong.
Over the past few weeks, I’ve been working on two seemingly unrelated areas of Flatpak permissions: conditional permissions and USB permissions. On paper, they looked like straightforward tasks. One involved understanding a relatively new Flatpak feature, while the other appeared to be a bug fix in Flatseal.
What I didn’t expect was that both tasks would teach me the same lesson: understanding the semantics of a system is often harder, and more important than writing the code itself.
Flatseal is a GNOME application that provides a graphical interface for managing Flatpak permissions. It gives users visibility into what applications can access and allows them to modify those permissions without manually editing override files.
At first glance, permissions seem simple. An application is either allowed to do something or it isn’t.
The reality is far more nuanced.
One of the first areas I explored was Flatpak’s conditional permissions. These permissions allow an application to request access only when certain runtime conditions are met.
Initially, I thought of permissions as static declarations. An application requests access to a resource, and Flatpak either grants it or denies it.
Conditional permissions challenge that assumption.
Instead of saying “always grant this permission,” an application can say “grant this permission only if a particular condition is true.”
The override file showing a conditional permission: if:x11:!has-wayland grants X11 access only when Wayland is unavailable.
The more I learned about the feature, the more I realized that permissions are not always permissions. Sometimes they are fallback mechanisms. Sometimes they are compatibility layers. Sometimes they exist purely because different systems support different capabilities.
This raised an interesting question for Flatseal.
If a permission only applies under certain conditions, how should that be represented to users? Should it be visible? Should it be editable? Should the interface expose the raw configuration or explain the effective behavior?
Those questions had less to do with coding and more to do with understanding the intent behind the feature.
While I was still thinking through those questions, I moved on to USB permissions.
That was when things became even more interesting. Flatpak exposes two related USB concepts:
Allowed USB devices
Blocked USB devices
These are represented internally through enumerable-devices and hidden-devices.
At first, this seemed straightforward. A device is either allowed or blocked. Then I started experimenting with flatpak override.
Flatseal’s USB section
I discovered that the same USB device can appear in both lists at the same time. Not only is this valid, but it is an expected configuration.
The key detail is that the hidden list always wins.
A device can be present in the allowed list and the blocked list simultaneously, and Flatpak will still treat it as blocked.
That discovery completely changed how I thought about the problem.
The original bug I was investigating involved removing USB devices through Flatseal’s interface. My initial assumption was simple: if a user removes a device from the allowed list, then the device should no longer be allowed.
But what does “remove” actually mean?
Does it mean deleting an override?
Does it mean explicitly blocking the device?
Does it mean restoring the original application defaults?
The answer depends on where the permission came from in the first place.
An original permission declared by an application is different from a permission added by the user. Removing those two things should not necessarily produce the same result.
What looked like a small UI interaction suddenly became a question about semantics.
I found myself spending more time reading source code, experimenting with Flatpak commands, and discussing expected behavior with maintainer and my mentor, Martin Abente, than writing actual implementation code.
At one point, I realized that I had been approaching the problem from the wrong direction entirely.
I was asking: “How should I implement this?”. The better question was: “What behavior is Flatpak trying to express?”
Only after answering that question could I determine how Flatseal should behave. That shift in mindset has probably been the most valuable lesson of this experience. As developers, we often think of programming as the process of building things.
Increasingly, I’m learning that a significant part of software engineering is understanding things.
Understanding why a feature exists.
Understanding the assumptions behind a design.
Understanding what users expect to happen.
Understanding what maintainers intended years before you ever opened the codebase.
The code is often the final step. The real work happens before that.
Looking back, neither conditional permissions nor USB permissions taught me the most important lesson. The lesson was that software behavior is defined by semantics, not implementation details.
A user clicks “remove” and expects a particular outcome.
A maintainer designs a feature with a specific meaning in mind.
A system applies rules according to semantics that may not be obvious from the UI.
Bridging those perspectives is where much of the engineering happens. And that’s exactly what has made contributing to Flatseal such a rewarding experience.
I started this journey expecting to write code. Instead, I learned how to ask better questions.
Ironically, that has probably made me a better engineer than the code itself ever could
The Flatpak website has been running on Middleman for years and time hasn't been kind. Touching the project resulted in seeing 42 vulnerability warnings. The gem itself hasn't seen an update in ages, and the dependency list is rather large.
Very recently, which happens to be 4 years ago, we've done a rebrand to reflect the fact that Flatpak has hit it big. There were a few hints of the old baggage, but overall it didn't feel like a website from 2007. But it was just lipstick.
For the layout, I reached for the same named-grid approach we designed for gnome.org. Instead of fighting with a rigid single column you get a multi-column grid with named areas. This allows you to escape the column to span across the whole width or do side-by-side layouts with overflow.
Most of the navigation is left to the footer. Another pattern we've embraced elsewhere and has worked well. A major simplification came from the great work of Kolja (razze) on Flathub -- all the distro setup instructions are maintained in one place.
Most benefits remain on the backend — keeping the site up to date won't be such a chore. Shoutout goes to Bart, AsciiWolf and Sebastian, thank you for caring. On to the next one!
Writing state machines gets a bit of a bad reputation because they are often implemented in complex manners which are specific to the problem domain. I think that makes people shy away from writing them when they are truly beneficial, including myself.
Where they often go awry is when you have some sort of work that needs to be done asynchronously. This is exceedingly common in UI programming like GTK applications but just as easily found in daemons.
Because of this, I see people explicitly avoiding the state machine, or worse, implicitly avoiding its correctness by open-coding a solution across a dozen callbacks.
With DexLimiter and DexFiber I find I can write these state machines better.
You can use the limiter with a max-concurrency of 1 to get an “asynchronous Mutex” of sorts. No lock management necessary.
Imagine, if you will, that a limiter is a mutex plus a callback/closure which fires as soon as a slot is free. That means we need a little state to send to our transition callback.
/* Define our closure state for a transition */
DEX_DEFINE_CLOSURE_TYPE (StateTransition, state_transition,
DEX_DEFINE_CLOSURE_OBJECT (PasswordDaemon, daemon),
DEX_DEFINE_CLOSURE_VALUE (PasswordDaemonMode, target))
That is a nice wrapper around defining a struct with a new and free function.
Now we can request a transition of the state machine. Since our DexLimiter is an asynchronous mutex (with a single runnable slot), the fiber will not be spawned until it is the highest priority.
That makes our transition code very clean when you combine the fiber with g_autoptr() and dex_await() to await the completion of futures. So a state machine might look like the following:
What I find nice about this is enter/leave transition components can be customized for the state machine transition. That leaves room for transitions between states which require specialization for correctness.
This is much cleaner than ad-hoc callbacks chained together because you can await in the transition fiber for asynchronous work to complete and the state machine itself is preserved. No shoving temporary state in your class instance. No testing hell to see if you caught all the failure cases. No pain with sequencing or order of main loop processing.
Hopefully that shows you can use libdex to write more correct and cleaner state machines by keeping the majority of the implementation in one place.
This week's icon is for
whitequark's project:
ChiPass:
"Store and autofill passwords"
Check out all weekly app icons created so far over here
and follow my icon creation adventures as they happen (including sketches) on
the Fediverse.
Need icons?
I love designing icons and am happy to contribute them
free of charge
when your project is Free and Open Source.
Funded by community sponsors
(every little helps!).
Lockpicker is a tool to recover passwords from a hash. Essentially it functions as a front-end for hashcat, making it possible to do password recovery without the hassle of hashcat syntax in a GNOME native graphical interface. It’s mainly useful for anyone that is curious about password recovery, security or as a companion app for CTF-challenges.
Learn 6502 Assembly (learn assembly programming on a virtual retro console) just shipped 0.7.0. The app now speaks Hebrew, fully translated by Menachem (@naattxx), who also tested and contributed the new right-to-left support. That makes Hebrew our first RTL language and prepares the app for more. This release also welcomes a new Indonesian translation by Arif Budiman, alongside the usual round of small fixes and improvements.
Whisp has surpassed 1,000 downloads this week within 15 days(I am in Awe, Thank you so so much). The application now includes several quality-of-life improvements, including the List module, tree-style lists for better organization, note pinning, and keyboard shortcuts for faster navigation.
Development is now moving into Phase 2, focused on expanding Whisp beyond note-taking. Planned features include a built-in Math Engine for calculations, unit and measurement conversions, and Image-to-Text functionality powered by OCR.
Thank you to everyone who has tried, reported issues, and contributed feedback. Community support has been invaluable in helping shape the project.
Gitte, a simple Git client for GNOME built with GTK4, libadwaita and Relm4, just got its 0.7.0 release! 🎉
The headline feature this time is a visual commit graph in the commit log: branches are drawn with color-coded lines, so commits off the mainline get a distinct per-branch color and it’s much easier to follow how history actually branches and merges. Stashes and pending changes show up as commits in that graph too, giving you a complete picture of your repository at a glance. You can also drop multiple commits at once now.
Diffs got a lot smarter as well. Gitte now detects renames, and the word-based diff has been overhauled to highlight intra-line changes more often. There’s also a new shortcut (Ctrl+D) to switch between staged and unstaged in the working copy view.
There’s more control over your lists and directories: you can toggle whether Gitte recurses into untracked directories, and the branch and tag lists now have a configurable sort order, with global defaults available in the preferences.
This release also comes with a broad UI overhaul. The main layout has been greatly reworked (special thanks to Brage Fuglseth!), and the preferences dialog is now a standard Adwaita preferences dialog. The columns now each have a distinct background color, the sidebar was reorganized, and the commit-graph and “rebase in progress” banners were revamped. On top of that come nice new action buttons in the sidebar, better spinners if an operations takes a bit longer, pane widths kept in sync across all views, and the usual round of consistent title casing and spacing fixes.
Under the hood there’s a performance pass too: file diff lists now show at most 100 files (30 expanded by default, with an option to force loading everything), more operations run asynchronously, and the diff view isn’t reloaded when it doesn’t need to be.
And of course there’s the usual pile of fixes: diff lines are redrawn on theme switch, scroll position is preserved while staging and unstaging, long labels break correctly, tag badges got a better color, and the window size is now saved correctly — including when quitting with Ctrl+Q.
It has been almost 2 years since I last posted about GDM Settings on TWIG. While there have been some releases during that time, the development wasn’t happening really consistently. I’m really sad to announce that the development of GDM Settings is on hold for now. I’m not sure when (or if) I’ll pick up the development of this app again.
For the two people out there that might be interested in trying out GIMP 0.54 from 1996 on your modern Linux system: Now you can, I created a Flatpak just for fun. It’s the last version using Motif before it’s creators decided to kick off a little toolkit called GTK… https://gitlab.gnome.org/balooii/gimp-0.54
GNOME OS is now using oo7 by default as a replacement of gnome-keyring-daemon, oo7-portal for the XDG Secrets portal implementation and oo7-cli as a replacement for secret-tool.
That’s all for this week!
See you next week, and be sure to stop by #thisweek:gnome.org with updates on your own projects!
From 2021 to 2023, I was really motivated to write articles regularly, but that is no longer the case. Most of my energy goes into programming nowadays. Whenever I try to write about a complicated topic in a digestible manner, I quickly lose motivation and don’t publish it.
For half a year, I’ve been trying to write an article about the thought process that went through when making the month view in GNOME Calendar accessible, as well as the implementation details. However, explaining complicated technical details into something that is simultaneously digestible to non-developers interested in accessibility and free and open-source calendar application developers requires me to withdraw my knowledge and assumptions, consider the perspective of someone who is not knowledgeable in this topic, and then recall the events that led me to take certain decisions, which demands a lot of energy.
Due to a lack of motivation, I want to try a different approach. I am calling this approach “draft-driven blogging”. Instead of publishing articles once they are complete, I will publish the draft publicly. This draft may contain keywords, incomplete sentences, random notes, empty sections and other characteristics that are only found in drafts. I will then iteratively improve the draft until it is considered finished.
This approach makes sense to me in terms of publishing and getting things done. I tend to seek perfection, which is great for maximizing quality, but it comes at the cost of motivation. Without external pressure, I am not motivated to fix something if it is not already publicly available. Seeing an unfinished blog post publicly is simply appalling. As it’s ugly, it motivates me to fix and complete it. So, instead of writing and publishing the ‘perfect’ article, I publish the ugly draft and complete it out of spite. Maybe “spite-driven blogging” is a better term for it?
Of course, communication is important. With drafts, I will add a disclaimer stating that the article in question is a draft. The published date will be the date of the last edit, and all previous drafts will be deleted. To avoid spamming RSS feeds and notifications, I will try to republish drafts infrequently.
It’s all an experiment; it might work well, or it might not. I might keep this approach or just pretend that I never tried it in the first place. We’ll see.
Check out all weekly app icons created so far over here
and follow my icon creation adventures as they happen (including sketches) on
the Fediverse.
Need icons?
I love designing icons and am happy to contribute them
free of charge
when your project is Free and Open Source.
Funded by community sponsors
(every little helps!).
I’m going to tell you about a big change I’m proposing for folks using Freedesktop SDK to build operating systems. And I’m also going to talk a bit about the GNOME Foundation elections. Maybe I’ll do that first.
GNOME Foundation elections
The GNOME Foundation is a democratically organised not-for-profit that grew from the GNOME open source project around the year 2000. Anyone who contributes to the GNOME open source project can be a member of the Foundation, which allows (among other things) periodically voting in a Board of Directors who govern the Foundation. You probably know all of this.
Back in 2001 the Foundation was a lively active space. Check out the election results from 2001: 11 candidates were selected out of 25 candidates, some of whom made pretty wild campaign promises such as banning all mentions of proprietary software.
When I became more involved in GNOME, ten or fifteen years ago, the Foundation seemed pretty boring and sensible and not many people volunteered to be directors. Here’s a mail from 2017 of someone complaining about not enough candidates and low voter turnout.
This year’s election has nine eight candidates for five seats, and a lively debate. Two years ago a big explosion happened in the community, and we are still dealing with the fallout and, in many cases, still piecing together what actually happened. (It seems like the explosion had been building for a long time and maybe the boring and sensible days of 2017 weren’t as boring and sensible as they appeared from outside.) I am not impressed by the tone of some of the discourse, everyone involved in the campaign believes in what they are doing and deserves respect, but it does make me optimistic about the future of the GNOME Foundation. Questioning things is healthier than ignoring them.
My quiet theory is that the dynamics of open source have changed fundamentally now that LLMs are a mainstream technology. Code is less of an asset than it ever was. A lot of work in the desktop space since 1997 has been simply keeping pace with the rest of the industry: Apple introduced glassy window bars and so we had to have them in GNOME too, Apple introduced “retina” displays and now we need fractional scaling, Apple introduced the App Store and now we need Flatpak, and so on. All of these are huge engineering efforts requiring a lot of new code.
So if code is not the asset, what is? The people, as it always ways. And in an increasingly hostile and untrustworthy internet, where you can’t even trust websites any more, a resilient autonomous and trusted structure like the GNOME Foundation, with a battle-tested democratic structure, and strong moderation capabilities to keep out the increasingly automated and vociferous trolls, is a very valuable thing indeed. (No wonder the trolls see it as a threat).
It’s hard to imagine a parallel universe where there’s no KDE eV and no GNOME Foundation, but I suspect we would miss both of them. Clearly all of the candidates believe in the Foundation enough to run for election. Remember that it’s an unpaid position with a lot of responsibility and minimal benefits. Being a director is a personal sacrifice. So thanks to everyone who keeps it working.
freedesktop-sdk.bst:public-stacks/runtime-gnu.bst
Onto the more technical material, I guess. The Freedesktop SDK is a widely used Flatpak app runtime that powers thousands of apps on Flathub. You probably know that, too.
Flatpak aimed from the beginning to be distro-independent, and consequently the Freedesktop SDK isn’t a repackaging of Debian or Fedora or Alpine Linux, but something more like a DIY Linux From Scratch build. As an app user you don’t notice any of this, because it’s very well executed and apps just work. Again, it’s hard now to imagine a parallel universe where the main Flatpak runtime was Fedora in a trenchcoat, but perhaps that would have impeded the success of Flatpak. (Of course Canonical still built their own app store technology, but I suspect that Canonical re-inventing things is part of every parallel universe).
So Freedesktop SDK has build instructions for common Linux tools, utilities and libraries, and they are so good that most BuildStream projects end up junctioning Freedesktop SDK to reuse them. (I covered this in more detail back in April). In theory this brings a virtuous cycle: we use FDSDK in industry and that funds maintenance and improvement of the build instructions, which in turn benefits the Flatpak runtime which doesn’t have any source of funding of its own.
I’ve been working on a slightly tricky intersection between these two worlds, which I call “Choose your own userland”. It makes a relatively small change to a stack element in Freedesktop SDK, but one which has big consequences for BuildStream projects that junction the project. (And no immediate consequences for Flatpak users, but you could see it as future-proofing).
A stack element is a group of elements. Freedesktop SDK provides various “public stacks” with useful element groupings. Most of these are related to build systems, like public-stacks/buildsystem-autotools.bst which includes everything you need to run builds with the crusty old GNU Autotools build system. Then there’s this special one: public-stacks/runtime-minimal.bst, which as of today includes the following:
Root filesystem symlinks
C/C++ platform libraries like GNU GLIBC,
The GNU Bash shell (and its dependencies Readline and ncurses)
GNU Coreutils, and all their dependencies
This stack is a recent addition, announced in the release notes of last year’s FDSDK 25.08 major release:
[BREAKING CHANGE] It’s now possible to create more minimal runtimes thanks to rework of bootstrap-import.bst. This adds a new stack public-stacks/buildsystem-make.bst which is essentially same as the original bootstrap-import.bst. There is also a new stack public-stacks/runtime-minimal.bst that is intended to provide a minimal environment that you can shell into. More info in the related issues: #1728 (closed), #1523
My selfish motivation for this change is I want to build embedded systems that don’t include GNU Bash and Coreutils at all, using BusyBox to provide the shell and utilities instead. This is hard today with FDSDK because every element unconditionally depends on Bash and Coreutils, so how can I remove them from my final system? But coincidentally, in the desktop world we are also seeing GNU Coreutils replaced with uutils/coreutils, a reimplementation in Rust which is already the default in Ubuntu since 25.10. So there’s another reason we might not want to hardcode a specific coreutils implementation in the lowest level stack.
The idea implemented in my branch came from Abderrahim and is delightfully simple: just drop Bash and Coreutils from the runtime-minimal stack, and have elements opt into them explictly.
On hearing the idea, I wasn’t sure how this would work, so of course I was effectively nerd-sniped into trying it. The result is as we’d hoped, it allows you to build systems with alternative coreutils. The FDSDK includes some example VMs, and here’s an example of one of them booting with uutils/coreutils (taken from MR!31779):
So the approach works. My main concern was the amount of churn we would cause if we change the meaning of runtime-minimal.bst. Of course, we often still want GNU Bash and GNU Coreutils, so my branch adds an additional public-stacks/runtime-gnu.bst element that brings in a GNU userland. I added Bash and Coreutils into all the public-stacks/buildsystem-*.bst elements too as we still want them at build time. That means that for most elements the change is actually transparent. You just need to ensure that each output explicitly includes a shell and utilities of your choice as runtime-depensd.
To test things further I tested the changes in branch of gnome-build-meta. It was pretty boring working through various build failures to get to a new dependency graph, but I came out the other side still convinced that this change is a good idea. (You can see my gnome-build-meta branch here, bearing in mind half the changes are actually dealing with differences between FDSDK 25.08 and ‘master’).
There was some lively discussion on the MR and I’m still not entirely clear if this change is going to land, much as I like it. One sticking point is a fear of landing big changes and not having enough people to deal with the fallout, and as an open source maintainer I certainly know that feeling, so I have more testing planned still.
Another complaint is that this change reneges on the promise from 25.08 about public-stacks/runtime-minimal.bst, that it “is intended to provide a minimal environment that you can shell into.“. You can’t shell into anything if there’s no shell, of course, so I can’t argue with the premise. But I am missing why this is a big deal. I’ve always had a bad time in BuildStream build shells because I just want to edit a file for testing and dammit there’s no Vim or even Vi or even Nano… in fact we don’t even seem to have less?! So I’ve always wanted a way to overlay elements with debug tools in my shell, and it turns out that “bst shell should be able to stage the specified element on top of a base element” is a feature request that’s been open since 2018.
If you use FDSDK as a junction and you like the idea then I’d appreciate comments on the MR. (If you hate the idea, I’m sure you’ve already switched tabs and are half way through posting an irate comment ;-). I am of course prepared for an outcome where this change doesn’t land, and it may indeed lead to some separation of “Linux OS & compiler bootstrap using BuildStream” and “Base Flatpak runtime” into different projects. My gut feeling is that this would be a bit like trying to carve a single grape into two pieces, i.e. there are still few enough people who actually want to maintain build instructions that it makes more sense to collaborate in the same repo.
Hello GNOME, This is a progress report on the Pitivi Timeline Ruler Rust rewrite.
Progress
We are rewriting the Pitivi Ruler in Rust and gtk4 snapshot logic to improve performance and memory safety. At its current stage the ruler is being constructed as a standalone widget in a personal repo that can be found here:
I am structuring this around rendering a single interval of ticks between two major ticks once, then stamping that across the duration of the project, as seen in draw_single_interval().
With the ticks stamped across the timeline I am then rendering a cache of Pango labels for the timestamps that are stamped across the visible window. I made the decision to use a BTreeMap for the cache for ease of iterating chronologically through the stamps and for dropping out-of-bounds keys. The logic for this cache handling primarily lives in update_label_cache().
After some feedback from members of the video editing community, I made the decision that minor ticks should always be clean multiples of frames in the time period. This logic is implemented in calculate_minor_divisions().
Next Steps
The primary goal I am focusing on next is implementing the gesture handling, including click and drag actions. Once gestures are implemented I am going to begin moving a lot of the math to traits so that I can write a mock_env and a live_env to start writing some unit testing.
































 The override file showing a conditional permission: if:x11:!has-wayland grants X11 access only when Wayland is unavailable.
The override file showing a conditional permission: if:x11:!has-wayland grants X11 access only when Wayland is unavailable.