Planet GNOME2024-04-27T11:03:57ZVenusGNOME Sysadmin Teamgnome-sysadmin@gnome.orghttps://planet.gnome.org/atom.xmlhttps://ramcq.net/?p=278Update from the GNOME boardIt’s been around 6 months since the GNOME Foundation was joined by our new Executive Director, Holly Million, and the board and I wanted to update members on the Foundation’s current status and some exciting upcoming changes. Finances As you may be aware, the GNOME Foundation has operated at a deficit (nonprofit speak for a […]
It’s been around 6 months since the GNOME Foundation was joined by our new Executive Director, Holly Million, and the board and I wanted to update members on the Foundation’s current status and some exciting upcoming changes.
Finances
As you may be aware, the GNOME Foundation has operated at a deficit (nonprofit speak for a loss – ie spending more than we’ve been raising each year) for over three years, essentially running the Foundation on reserves from some substantial donations received 4-5 years ago. The Foundation has a reserves policy which specifies a minimum amount of money we have to keep in our accounts. This is so that if there is a significant interruption to our usual income, we can preserve our core operations while we work on new funding sources. We’ve now “hit the buffers” of this reserves policy, meaning the Board can’t approve any more deficit budgets – to keep spending at the same level we must increase our income.
One of the board’s top priorities in hiring Holly was therefore her experience in communications and fundraising, and building broader and more diverse support for our mission and work. Her goals since joining – as well as building her familiarity with the community and project – have been to set up better financial controls and reporting, develop a strategic plan, and start fundraising. You may have noticed the Foundation being more cautious with spending this year, because Holly prepared a break-even budget for the Board to approve in October, so that we can steady the ship while we prepare and launch our new fundraising initiatives.
Strategy & Fundraising
The biggest prerequisite for fundraising is a clear strategy – we need to explain what we’re doing and why it’s important, and use that to convince people to support our plans. I’m very pleased to report that Holly has been working hard on this and meeting with many stakeholders across the community, and has prepared a detailed and insightful five year strategic plan. The plan defines the areas where the Foundation will prioritise, develop and fund initiatives to support and grow the GNOME project and community. The board has approved a draft version of this plan, and over the coming weeks Holly and the Foundation team will be sharing this plan and running a consultation process to gather feedback input from GNOME foundation and community members.
In parallel, Holly has been working on a fundraising plan to stabilise the Foundation, growing our revenue and ability to deliver on these plans. We will be launching a variety of fundraising activities over the coming months, including a development fund for people to directly support GNOME development, working with professional grant writers and managers to apply for government and private foundation funding opportunities, and building better communications to explain the importance of our work to corporate and individual donors.
Board Development
Another observation that Holly had since joining was that we had, by general nonprofit standards, a very small board of just 7 directors. While we do have some committees which have (very much appreciated!) volunteers from outside the board, our officers are usually appointed from within the board, and many board members end up serving on multiple committees and wearing several hats. It also means the number of perspectives on the board is limited and less representative of the diverse contributors and users that make up the GNOME community.
Holly has been working with the board and the governance committee to reduce how much we ask from individual board members, and improve representation from the community within the Foundation’s governance. Firstly, the board has decided to increase its size from 7 to 9 members, effective from the upcoming elections this May & June, allowing more voices to be heard within the board discussions. After that, we’re going to be working on opening up the board to more participants, creating non-voting officer seats to represent certain regions or interests from across the community, and take part in committees and board meetings. These new non-voting roles are likely to be appointed with some kind of application process, and we’ll share details about these roles and how to be considered for them as we refine our plans over the coming year.
Elections
We’re really excited to develop and share these plans and increase the ways that people can get involved in shaping the Foundation’s strategy and how we raise and spend money to support and grow the GNOME community. This brings me to my final point, which is that we’re in the run up to the annual board elections which take place in the run up to GUADEC. Because of the expansion of the board, and four directors coming to the end of their terms, we’ll be electing 6 seats this election. It’s really important to Holly and the board that we use this opportunity to bring some new voices to the table, leading by example in growing and better representing our community.
Allan wrote in the past about what the board does and what’s expected from directors. As you can see we’re working hard on reducing what we ask from each individual board member by increasing the number of directors, and bringing additional members in to committees and non-voting roles. If you’re interested in seeing more diverse backgrounds and perspectives represented on the board, I would strongly encourage you consider standing for election and reach out to a board member to discuss their experience.
Thanks for reading! Until next time.
Best Wishes, Rob President, GNOME Foundation
Update 2024-04-27: It was suggested in the Discourse thread that I clarify the interaction between the break-even budget and the 1M EUR committed by the STF project. This money is received in the form of a contract for services rather than a grant to the Foundation, and must be spent on the development areas agreed during the planning and application process. It’s included within this year’s budget (October 23 – September 24) and is all expected to be spent during this fiscal year, so it doesn’t have an impact on the Foundation’s reserves position. The Foundation retains a small % fee to support its costs in connection with the project, including the new requirement to have our accounts externally audited at the end of the financial year. We are putting this money towards recruitment of an administrative assistant to improve financial and other operational support for the Foundation and community, including the STF project and future development initiatives.
(also posted to GNOME Discourse, please head there if you have any questions or comments)
2024-04-26T10:39:06Z2024-04-26T10:39:06Zramcqhttps://ramcq.netThe personal blog of Robert McQueenRobotic Tendencies2024-04-27T08:16:35Zhttps://thisweek.gnome.org/posts/2024/04/twig-145/#145 Quality Over Quantity
Update on what happened across the GNOME project in the week from April 19 to April 26.
GNOME Core Apps and Libraries
GTK
Cross-platform widget toolkit for creating graphical user interfaces.
This release changes the default GSK renderer to be Vulkan, on Wayland. Other platforms still use ngl.
The intent of this change is to get wider testing and verify that Vulkan drivers are good enough for us to rely on. If significant problems show up, we will revert this change for 4.16.
You can still override the renderer choice using the GSK_RENDERER environment variable.
This release also changes font rendering settings by introducing a new high-level gtk-font-rendering settings which gives GTK more freedom to decide on font rendering.
You can still use the low-level font-related settings by changing the new property to ‘manual’.
If you are building GTK for a distribution, notice that some deprecated build options have been removed.
I’ve released a new version of Hieroglyphic. This version features a new app icon by Tobias Bernard, refines the UI and improves the symbol recognition speed. You can download it from Flathub.
This week we released version 1.8 of Graphs. This release mostly focuses on background changes to the code, but there’s still a number of nice quality of life changes that are interesting to highlight:
Graphs now has full support for touchscreen devices
Equation handling has been improved. Now it is no longer needed to add a * symbol between every single parameter upon multiplication, instead an equation such as y = 4sin(2x + pi) is handled without any issues.
Support has been added for additional trigonometric functions and their inverses, such as sinh and cosh. Now the vast majority of trig functions should work without any issues.
Help has been ported to Yelp, and can now be accesed directly from the app. This documentation is still a work in progress and will be expanded upon throughout this release cycle.
There is now a warning when editing a style with poor contrast between the labels and background colours.
Numerical entries throughout the application now indicate whenever an invalid input is given.
Multiple bug fixes were implemented, especially with regard to the equation handling in the curve fitting dialog.
Many different improvements have been added to the translation process such as more translatable strings, and added context to strings. Thanks for the feedback from the translation team :)
As always, the latest release can be found on Flathub. For any feedback, suggestions or bug reports, please file an issue at the GitLab issue tracker.
The board of the GNOME Foundation is pleased to share an update about finances, strategy, fundraising, and our exciting plans to bring more diverse and inclusive representation into how the Foundation is governed and can best support and promote the GNOME community. We’re adding two seats to the board from the upcoming election which starts next month, and are interested to speak with prospective candidates about what’s involved and how they can help.
That’s all for this week!
See you next week, and be sure to stop by #thisweek:gnome.org with updates on your own projects!
2024-04-26T00:00:00Z2024-04-26T00:00:00Zhttps://thisweek.gnome.org/author/felix/Felix HäckerRecent content in Felix on This Week in GNOMEFelix on This Week in GNOME2024-04-26T00:00:00Zhttps://olea.org/diario/2024/04/26/Small_GLAM_Slam_project__update.htmlSmall GLAM Slam Pilot 1 project update
This is a project update for the SGS Pilot 1 project. This is a WMF funded project (ID: 22444585).
You can observe que are now using the coined term «Very Small GLAM». This will be the activity scope from now as we consider it short and and precise. The Small GLAM Slam denomination will be kept for the ID: 22444585 project.
What the Very Small GLAM term refers to? It identifies GLAM entities of very small size. How small? We got the inspiration from the concept of VSE (very small entities) coined for the ISO/IEC 29110 Series for software development entities up to 25 members. To set a focus we, a bit arbitrarily, chose the number 5 as «up to 5» members an institution or team working in GLAM. Very Small GLAM non circunscribes to Open GLAM, but Open GLAM would probably be the best approach or complement for this teams with not so much resources.
Wikimedia LEADS spin-off
An unexpected spin-off has been the conceptualization of the new initiative, Wikimedia LEADS (Learning Ecosystems and Ameliorating Data Space) when attending EU’s Next Generation Internet (NGI) funding call. The goal is to develop an advanced learning free/open data space and software ecosystem for the Wikimedia Movement.
Wikimedia LEADS first goal is to attend the GLAM Wiki learning needs. GLAM Wiki also shares a lot of commonalities with the Europeana community.
By extension, all practices, tools and many of the specific contents will be applicable to all other areas of the human knowledge.
Project’s activity areas
The SGS Pilot 1 is now structured in these work-packages:
WP1—IT system developed with the NAS killer concept with a free software stack for GLAM;
WP2—configuration for a locally installed Wikibase suite;
WP3—GLAM ontologies and vocabularies;
WP4—GLAM practices.
WP1—IT system, update
The selected operating system is UNRAID. The technical justifications are:
it’s a Linux distribution;
it features the ZFS file system, probably the best alternative for data preservation;
has a graphic administration interface
and run on any PC compatible hardware.
At this point the most important update about UNRAID is, since the grant approval, it changed their licensing model and fees.
Current project hardware details are:
a received a donated HP Z400 system, which happily includes an SSD disk;
procured 24 GB of ECC RAM, PC3-10600E, the maximum supported by the board.
In the next days we’ll buy the three HGST hard drives and other minor components for the firsts tests.
For the system configuration development phase, we’ll use another lend computer as a test server.
Software systems
This is a proposal of software architecture for a local installation of Wikibase in a GLAM context:
There is not advances to report about software.
WP2—Wikibase suite configuration, update
As we are not still familiar with the Wikibase ecosystem we are practicing setting up some instances in Wikibase.cloud.
Also, we are starting to identify relevant Wikibase features. We are using wikibase.world as inventory of:
Here we have the most juicy results for the moment. After a papers research we identified the CIDOC Conceptual Reference Model (CIDOC-CRM) as an international reference model for museums. It’s more relevant when you find it’s being used as a reference for mapping or extending to other domains like CRMdig (digitalization) and CRMsoc (social phenomena and constructs), which are relevant for the «Memorias del Cine» archive. Very relevant is the availability of a CRM OWL ontology (non official, but apparently up to date) and some minor Wikidata mapping (https://w.wiki/9r$s, 24 items)
Also, we identified the Records in Contexts–Conceptual Model (RiC-CM), whose ontology is also published in OWL format. RiC-CM is a reference for archival and we found initial works for CRM <-> RiC-CM mapping. The current mapping with Wikidata is anecdotal (https://w.wiki/9sAh, 4 items).
In the context of models of practices we are learning about SEMAT Essence. The formal specifications are expressed in text and in a UML metamodel file (.xmi). The concept of metamodel is practically equivalent to the LOD ontology. It took a while but now we know more about how to manage this XMI formats using Magic Draw. The plan is to import the ontology to Wikibase using the same tools than for CRM and related. We found the Essence «Package Competency» model is relevant for populating a map of competences/abilities for the Movement, as Wikimedia LEADS proposes.
For managing this information we are getting familiar with tools like Protégé, Fuseki, Magic Draw and some others.
A very happily discovery has been a couple set of tools for mapping and importing to Wikibase ontologies based in CIDOC-CRM. They are output of the projects SAF-Lux and GeoKB. We expect we’ll make intensive use of them or their derivatives.
There is not so much real work on this side, since we are not ready to work modeling with Essence. But we are collecting some relevant bibliography for the project scope:
C. Matos, Manual práctico para la digitalización de colecciones para difusión digital, 2022.
A. Salvador Benítez, Ed., Patrimonio fotográfico: de la visibilidad a la gestión. en Biblioteconomía y administración cultural, no. 280. Gijón: Trea, 2015.
J. M. Sánchez Vigil, A. Salvador Benítez, y M. Olivera Zaldua, Colecciones y fondos fotográficos: criterios metodológicos, estrategias y protocolos de actuación, Primera edición. en Museología y patrimonio cultural. Gijón: Ediciones Trea, 2022.
Collections Trust, Spectrum 5.1: UK Collections Management Standard, 2022.
Centro de Fotografía de Motevideo, Guía del archivo fotográfico, 2017.
L. Bountouri, Archives in the digital age: standards, policies and tools. en Chandos Information Professional Series. Cambridge, MA: Chandos Publishing, an imprint of Elsevier, 2017.
In the next days we’ll procure the pending hardware component to set up the server prototype. Then we’ll define the configuration and procedure to set up an UNRAID server instance ready for data preservation tasks. Then we’ll migrate the multimedia archive of «Memorias del Cine» to the server. The fun part of cataloging the archive in Wikibase would start as soon as we have an stable ontology model for digital archives.
Also, in May I’ll be attending the Wikimedia Hackathon in Tallinn and the AI Sauna in Helskinki. Reach me there in person if you are interested in our work.
2024-04-25T22:00:00Z2024-04-25T22:00:00Zhttps://olea.org/Ismael OleaPastoreando procomunes desde 1994 — Shepherding the commons since 1994
- just the English postsIsmael Olea — web personal2024-04-26T18:44:00Zhttps://blogs.gnome.org/chergert/?p=11896Collaborating on Builder
It’s no secret I have way more projects to manage than hours in the day. I hope to rectify this by sharing more knowledge on how my projects are built. The most important project, Builder, is quite a large code-base. It is undoubtedly daunting to dive in and figure out where to start. Here is … Continue reading Collaborating on Builder
It’s no secret I have way more projects to manage than hours in the day.
I hope to rectify this by sharing more knowledge on how my projects are built. The most important project, Builder, is quite a large code-base. It is undoubtedly daunting to dive in and figure out where to start.
Here is a sort of engineers journal (PDF) in book form about how the components fit together. The writing tries to be brief and to the point. You can always reference the source code for finer points.
There is so much more that can happen with Builder if we have regular contributors and subsystem maintainers.
We still need to bring back a new designer. We still need real strong git commit integration. We still need a physical device simulator to go with our architecture emulator. Our debugger API could use data visualizers and support for the debug-adapter-protocol. Container integration has a long tail of desired features.
You get the idea.
Lots of exciting features will happen once people dive into the code-base to learn more. Hopefully this book helps you along that journey.
2024-04-24T22:14:01Z2024-04-24T22:14:01Zchergerthttps://blogs.gnome.org/chergertDetails of Christian's work on GNOMEHappenings in GNOME2024-04-24T22:14:01Zhttps://tirania.org/blog/archive/2024/Apr-23.html23 Apr 2024
Embeddable Game Engine
Many years ago, when working at Xamarin, where we were building cross-platform
libraries for mobile developers, we wanted to offer both 2D and 3D gaming
capabilities for our users in the form of adding 2D or 3D content to their
mobile applications.
For 2D, we contributed and developed assorted Cocos2D-inspired libraries.
For 3D, the situation was more complex. We funded a few over the years, and we
contributed to others over the years, but nothing panned out (the
history of this is worth a dedicated post).
Around 2013, we looked around, and there were two contenders at the
time, one was an embeddable engine with many cute features but not great UI
support called Urho, and the other one was a Godot, which had a great IDE, but
did not support being embedded.
I reached out to Juan at the time to discuss whether Godot could be turned into
such engine. While I tend to take copious notes of all my meetings, those
notes sadly were gone as part of the Microsoft acquisition, but from what I can
remember Juan told me, "Godot is not what you are looking for" in two dimensions,
there were no immediate plans to turn it into an embeddable library, and it was
not as advanced as Urho, so he recommended that I go with Urho.
We invested heavily in binding Urho and created
UrhoSharp that would go into becoming a great
3D library for our C# users and worked not only on every desktop and mobile
platform, but we did a ton of work to make it great for AR and VR headsets.
Sadly, Microsoft's management left UrhoSharp to die.
Then, the maintainer of Urho stepped down, and Godot became one of the most
popular open-source projects in the world.
Last year, @Faolan-Rad contributed a patch to Godot to turn it into a library
that could be embedded into applications. I used this library to build
SwiftGodotKit and have been
very happy with it ever since - allowing people to embed Godot content into
their application.
However, the patch had severe limitations; it could only ever run one Godot game as
an embedded system and could not do much more. The folks at Smirk
Software wanted to take this further. They wanted to host
independent Godot scenes in their app and have more control over those so
they could sprinkle Godot content at their heart's content on their mobile app (demo)
They funded some initial work to do this and hired Gergely
Kis's company to do this work.
Gergely demoed this work at GodotCon last year. I came back very excited from
GodotCon and I decided to turn my prototype Godot on iPad into a complete
product.
One of the features that I needed was the ability to embed chunks of Godot in
discrete components in my iPad UI, so we worked with Gergely to productize and
polish this patch for general consumption.
Now, there is a complete patch under review to allow people to embed arbitrary
Godot scenes into their apps. For SwiftUI users, this means that you can embed a Godot scene into a View and display and control it at will.
Hopefully, the team will accept this change into Godot, and once this is done, I will
update SwiftGodotKit to get these new capabilities to Swift users (bindings for
other platforms and languages are left as an exercise to the reader).
It only took a decade after talking to Juan, but I am back firmly in Godot land.
2024-04-24T01:41:00Z2024-04-24T01:41:00ZMiguel de Icazamiguel.de.icaza@gmail.comhttps://tirania.org/blog//index.htmlmiguel.de.icaza@gmail.comMiguel de IcazaMiguel de Icaza's BlogMiguel de Icaza2024-04-23T21:41:00Zhttps://blogs.gnome.org/shell-dev/?p=3094Notifications in 46 and beyond
One of the things we’re tackling as part of the STF infrastructure initiative is improving notifications. Other platforms have advanced significantly in this area over the past decade, while we still have more or less the same notifications we had since the early GNOME 3 days, both in terms of API and feature set. There’s …
One of the things we’re tackling as part of the STF infrastructure initiative is improving notifications. Other platforms have advanced significantly in this area over the past decade, while we still have more or less the same notifications we had since the early GNOME 3 days, both in terms of API and feature set. There’s plenty to do here
The notification drawer on GNOME 45
Modern needs
As part of the effort to port GNOME Shell to mobile Jonas looked into the delta between what we currently support and what we’d need for a more modern notification experience. Some of these limitations are specific to GNOME’s implementation, while others are relevant to all desktops.
Tie notifications to apps
As of GNOME 45 there’s no clear identification on notification bubbles which app they were sent by. Sometimes it’s hard to tell where a notification is coming from, which can be annoying when managing notifications in Settings. This also has potential security implications, since the lack of identification makes it trivial to impersonate other apps.
We want all notifications to be clearly identified as coming from a specific app.
Global notification sounds
GNOME Shell can’t play notification sounds in all cases, depending on the API the app is using (see below). Apps not primarily targeting GNOME Shell directly tend to play sounds themselves because they can’t rely on the system always doing it (it’s an optional feature of the XDG Notification API which different desktops handle differently). This works, but it’s messy for app developers because it’s hard to test and they have to implement a fallback sound played by the app. From a user perspective it’s annoying that you can’t always tell where sounds are coming from because they’re not necessarily tied to a notification bubble. There’s also no central place to manage the notification behavior and it doesn’t respect Do Not Disturb.
Notification grouping
Currently all notifications are just added to a single chronological list, which gets messy very quickly. In order to limit the length of the list we only keep the latest 3 notifications for every app, so notifications can disappear before you have a chance to act on them.
Other platforms solve this by grouping notifications by app, or even by message thread, but we don’t have anything like this at the moment.
Notifications grouped by app on the iOS lock screen
Expand media support
Currently each notification bubble can only contain one (small) image. It’s mostly used for user avatars (for messages, emails, and the like), but sometimes also for actual content (e.g. a thumbnail for the image someone sent).
Ideally what we want is to be able to show larger images in addition to avatars, as the actual content of the notification.
As of GNOME 45 we only have a single slot for images on notifications, and it’s too small for actual content.Other platforms have multiple slots (app icon, user avatar, and content image), and media can be expanded to much larger sizes.
There’s also currently no way to include descriptive text for images in notifications, so they are inaccessible to screen readers. This isn’t as big a deal with the current icons since they’re small and mostly used for ornamental purposes, but will be important when we add larger images in the body.
Updating notification content
It’s not possible for apps to update the content inside notifications they sent earlier. This is needed to show progress bars in notifications, or updating the text if a chat message was modified.
How do we get there?
Unfortunately, it turns out that improving notifications is not just a matter of standardizing a few new features and implementing them in GNOME Shell. The way notifications work today has grown organically over the years and the status quo is messy. There are three different APIs used by apps today: XDG Notification, Gio.Notification, and XDG Portal.
How different notification APIs are used today
XDG Notification
This is the Freedesktop specification for a DBus interface for apps to send notifications to the system. It’s the oldest notification API still in use. Other desktops mostly use this API, e.g. KDE’s KNotification implements this spec.
Somewhat confusingly, this standard has never actually been finalized and is still marked as a draft today, despite not having seen significant changes in the past decade.
Gio.Notification
This is an API in GLib/Gio to send notifications, so it’s only used by GTK apps. It abstracts over different OS notification APIs, primarily the XDG one mentioned above, a private GNOME Shell API, the portal API, and Cocoa (macOS).
The primary one being used is the private DBus interface with GNOME Shell. This API was introduced in the early GNOME 3 days because the XDG standard API was deemed too complicated and was missing some features (in particular notifications were not tied to a specific app).
When using Gio.Notification apps can’t know which backend is used, and how a notification will be displayed or behave. For example, notifications can only persist after the app is closed if the private GNOME Shell API is used. These differences are specific to GNOME Shell, since the private API is only implemented there.
XDG Portal
XDG portals are secure, standardized system APIs for the Linux desktop. They were introduced as part of the push for app sandboxing around Flatpak, but can (and should) be used by non-sandboxed apps as well.
The XDG notification portal was inspired by the private GNOME Shell API, with some additional features from the XDG API mixed in.
XDG portals consist of a frontend and a backend. In the case of the notification portal, apps talk to the frontend using the portal API, while the backend talks to the system notification API. Backends are specific to the desktop environment, e.g. GNOME or KDE. On GNOME, the backend uses the private GNOME Shell API when possible.
The plan
From the GNOME Shell side we have the XDG API (used by non-GNOME apps), and the private API (used via Gio.Notification by GNOME apps). From the app side we additionally have the XDG portal API. Neither of these can easily supersede the others, because they all have different feature sets and are widely used. This makes improving our notifications tricky, because it’s not obvious which of the APIs we should extend.
After several discussions over the past few months we now have consensus that it makes the most sense to invest in the XDG portal API. Portals are the future of system APIs on the free desktop, and enable app sandboxing. Neither of the other APIs can fill this role.
Our plan for notification APIs going forward: Focus on the portal API
This requires work in a number of different modules, including the XDG portal spec, the XDG portal backend for GNOME, GNOME Shell, and client libraries such as Gio.Notification (in GLib), libportal, libnotify, and ashpd.
In the XDG portal spec, we are adding support for a number of missing features:
Tying notifications to apps
Grouping by message thread
Larger images in the notification body
Special notifications for e.g. calls and alarms
Clearing up some instances of undefined behavior (e.g. markup in the body, playing sounds, whether to show notifications on the lock screen, etc.)
The long-term goal is for apps to switch to the portal API and deprecate both of the others as application-facing APIs. Internally we will still need something to communicate between the portal backend and GNOME Shell, but this isn’t public API so we’re much more flexible here. We might expand either the XDG API or the private GNOME Shell protocol for this purpose, but it has not been decided yet how we’ll do this.
What we did in GNOME 46
When we started the STF project late last year we thought we could just pull the trigger on a draft proposal Jonas for an API with the new capabilities needed for mobile. However, as we started discussing things in more detail we realized that this was the the wrong place to start. GNOME Shell already didn’t implement a number of features that are in the XDG notification spec, so standardizing new features was not the main blocker.
The code around notifications in GNOME Shell has grown historically and has seen multiple major UI redesigns since GNOME 3.0. Additional complexity comes from the fact that we try to avoid breaking extensions, which means it’s difficult to e.g. change function names or signatures. Over time this has resulted in technical debt, such as weird anachronistic structures and names. It was also not using many of the more recent GJS features which didn’t exist yet when this code was written originally.
Anyone remember that notifications used to be on the bottom? This is what they looked like in GNOME 3.6 (2012).
As a first step we restructured and cleaned up legacy code, ported it to the most recent GJS features, updated the coding style, and so on. This unfortunately means extensions need to be updated, but it puts us on much firmer ground for the future.
With this out of the way we added the first batch of features from our list above, namely adding notification headers, expanding notifications in the drawer, larger icons, and some style fixes to icons. We also fixed a very annoying issue with “App is ready” notifications not working as expected when clicking a notification (!3198 and !3199).
We also worked on a few other things that didn’t make it in time for 46, most notably grouping notifications by app (which there’s a draft MR for), and additionally grouping them by thread (prototype only).
With all the groundwork laid in GNOME 46 and the spec draft mostly ready we’re in a good position to continue iterating on notifications in 47 and beyond. In GNOME 47 we want to add some of the first newly spec’d features, in particular notification sounds, markup support in the body, and display hints (e.g. showing on the lock screen or not).
We also want to continue work on the UI to unlock even more improvements in the future. In particular, grouping by app will allow us to drop the “only keep 3 notifications per app” behavior and will generally make notifications easier to manage, e.g. allowing to dismiss all notifications from a given app. We’re also planning to work on improving keyboard navigation and ensuring all content is accessible to screen readers.
Due to the complex nature of the UI for grouping by app and the many moving parts with moving forward on the spec it’s unclear if we’ll be able to do more than this in the scope of STF and within the 47 cycle. This means that additional features that require the new spec and/or lots of UI work, such as grouping by thread and custom UI for call or alarm notifications will probably be 48+ material.
Conclusion
As we hope this post has illustrated, notifications are way more complex than they might appear. Improving them requires untangling decades of legacy stuff across many different components, coordinating with other projects, and engaging with standards bodies. That complexity has made this hard to work on for volunteers, and there has not been any recent corporate interest in the area, which is why it has been stagnant for some time.
The Sovereign Tech Fund investment has allowed us to take the time to properly work through the problem, clean up technical debt, and make a plan for the future. We hope to leverage this momentum over the coming releases, for a best-in-class notification experience on the free desktop. Stay tuned
2024-04-23T13:01:29Z2024-04-23T13:01:29Zjsparberhttps://blogs.gnome.org/shell-devDevelopment blog for GNOME Shell and MutterGNOME Shell & Mutter2024-04-24T16:17:56Ztag:blogger.com,1999:blog-5968355124473522212.post-4205566450549309916C is dead, long live C (APIs)
In the 80s and 90s software development landscape was quite different from today (or so I have been told). Everything that needed performance was written in C and things that did not were written in Perl. Because computers of the time were really slow, almost everything was in C. If you needed performance and fast development, you could write a C extension to Perl.
As C was the only game in town, anyone could use pretty much any other library directly. The number of dependencies available was minuscule compared to today, but you could use all of them fairly easily. Then things changed, as they have a tendency to do. First Python took over Perl. Then more and more languages started eroding C's dominant position. This lead to a duplication of effort. For example if you were using Java and wanted to parse XML (which was the coolness of its day), you'd need an XML parser written in Java. Just dropping libxml in your Java source tree would not cut it (you could still use native code libs but most people chose not to).
The number of languages and ecosystems kept growing and nowadays we have dozens of them. But suppose you want to provide a library that does something useful and you'd like it to be usable by as many people as possible. This is especially relevant for providing closed source libraries but the same applies to open source libs as well. You especially do not want to rewrite and maintain multiple implementations of the code in different languages. So what do you do?
Let's start by going through a list of programming languages and seeing what sort of dependencies they can use natively (i.e. the toolchain or stdlib provides this support out of the box rather than requiring an addon, code generator, IDL tool or the like)
C: C
Perl: Perl and C
Python: Python and C
C++: C++ and C
Rust: Rust and C
Java: Java and C
Lua: Lua and C
D: D, subset of C++ and C
Swift: Swift, Objective C, C++ (eventually?) and C
PrettyMuchAnyNewLanguage: itself and C
The message is quite clear. The only thing in common is C, so that is what you have to use. The alternative is maintaining an implementation per language leaving languages you explicitly do not support out in the cold.
So even though C as a language is (most likely) going away, C APIs are not. In fact, designing C APIs is a skill that might even see a resurgence as the language ecosystem fractures even further. Note that providing a library with a C API does not mean having to implement it in C. All languages have ways of providing libraries whose external API is compatible with C. As an extreme example, Visual Studio's C runtime libraries are nowadays written in C++.
CapyPDF's design and things picked up along the way
One of the main design goals of CapyPDF was that it should provide a C API and be usable from any language. It should also (eventually) provide a stable API and ABI. This means that the ground truth of the library's functionality is the C header. This turns out to have design implications to the library's internals that might be difficult to add in after the fact.
Hide everything
Perhaps the most important declaration in widely usable C headers is this.
typedef struct _someObject SomeObject;
In C parlance this means "there is a struct type _someObject somewhere, create an alias to it called SomeObjectType". This means that the caller can create pointers to structs of type SomeObject but do nothing else with them. This leads to the common "opaque structs" C API way of doing things:
This permits you to change the internal representation of the object while still maintaining stable public API and ABI. Avoid exposing the internals of structs whenever possible, because once made public they can never be changed.
Objects exposed via pointers must never move in memory
This one is fairly obvious when you think about it. Unfortunately it means that if you want to give users access to objects that are stored in an std::vector, you can't do it with pointers, which is the natural way of doing things in C. Pushing more entries in the vector will eventually cause the capacity to be exceeded so the storage will be reallocated and entries moved to the new backing store. This invalidates all pointers.
There are several solutions to this, but the simplest one is to access those objects via type safe indices instead. They are defined like this:
typedef struct { int32_t id; } SomeObjectId;
This struct behaves "like an integer" in that you can pass it around as an int but it does not implicitly convert to any other "integer" type.
Objects must be destructable in any order
It is easy to write into documentation that "objects of type X must be destroyed before any object Y that they use". Unfortunately garbage collected languages do not read your docs and thus provide no guarantee whatsoever on object destruction order. When used in this way any object must be destructable at any time regardless of the state of any other object.
This is the opposite of how modern languages want to work. For the case of CapyPDF especially page draw contexts were done in an RAII style where they would submit their changes upon destruction. For an internal API this is nice and usable but for a public C API it is not. The implicit action had to be replaced with an explicit function to add the page that takes both object pointers (the draw context and document) as arguments. This ensures that they both must exist and be valid at the point of call.
Use transactionality whenever possible
It would be nice if all objects were immutable but sadly that would mean that you can't actually do anything. A library must provide ways for end users to create, mutate and destroy objects. When possible try to do this with a builder object. That is, the user creates a "transactional change" that they want to do. They can call setters and such as much as they want, but they don't affect the "actual document". All of this new state is isolated in the builder object. Once the user is finished they submit the change to the main object which is then validated and either rejected or accepted as a whole. The builder object then becomes an empty shell that can be either reused or discarded.
CapyPDF is an append only library. Once something has been "committed" it can never be taken out again. This is also something to strive towards, because removing things is a lot harder than adding them.
Prefer copying to sharing
When the library is given some piece of data, it makes a private copy of it. Otherwise it would need to coordinate the life cycle of the shared piece of data with the caller. This is where bugs lie. Copying does cost some performance but makes a whole class of difficult bugs just go away. In the case of CapyPDF the performance hit turned out not to be an issue since most of the runtime is spent compressing the output with zlib.
Every function call can fail, even those that can't
Every function in the library returns an error code. Even those that have no way of failing, because circumstances can change in the future. Maybe some input that could be anything somehow needs to be validated now and you can't change the function definition as it would break API. Thus every function returns an error code (except the function that converts an error code into an error string). Sadly this means that all "return values" must be handled via out parameters.
ErrorCode some_object_new(SomeObject **out_ptr);
This is not great, but such is life.
Think of C APIs as "in-process RPC"
When designing the API of CapyPDF it was helpful to think of it like a call to a remote endpoint somewhere out there on the Internet. This makes you want to design functions that are as high level as possible and try to ignore all implementation details you can, almost as if the C API was a slightly cumbersome DSL.
2024-04-21T13:39:00Z2024-04-21T13:39:00ZJussinoreply@blogger.comhttp://www.blogger.com/profile/03370287682352908292tag:blogger.com,1999:blog-5968355124473522212Jussinoreply@blogger.comhttp://www.blogger.com/profile/03370287682352908292A gathering of development thoughts of Jussi Pakkanen. Some of you may know him as the creator of the Meson build system. jpakkane at gmail dot comNibble Stew2024-04-22T10:26:11Zhttps://meeksfamily.uk/~michael/blog/2024/04/20/2024-04-202024-04-20 Saturday
Off to see R&A's new daughter; exciting.
Caught up with blog in the car, up-loaded some slides
on background save from COOL days.
2024-04-20T10:03:39Z2024-04-20T10:03:39Zhttps://meeksfamily.uk/~michael/blog/index.atomMichael Meeksmichael.meeks@collabora.comhttps://meeksfamily.uk/~michael/blog/index.atomCopyright 1999-2015 Michael Meeksthings, of varying degrees of uselessness, that I didStuff Michael Meeks is doing2024-04-20T10:03:39Zhttps://meeksfamily.uk/~michael/blog/2024/04/19/2024-04-192024-04-19 Friday
Encouraging design call; lunch, all afternoon
workshop. Fixed a couple of bugs, slugged in the evening.
Steeled myself to re-subscribe to the Economist -
very disappointed by the rules on the Digital subscription
making it un-share-able; who would spend that much per
person in their household, to replace a paper copy that
can be shared ?
2024-04-19T21:00:00Z2024-04-19T21:00:00Zhttps://meeksfamily.uk/~michael/blog/index.atomMichael Meeksmichael.meeks@collabora.comhttps://meeksfamily.uk/~michael/blog/index.atomCopyright 1999-2015 Michael Meeksthings, of varying degrees of uselessness, that I didStuff Michael Meeks is doing2024-04-20T10:03:39Zhttps://blogs.gnome.org/chergert/?p=11821Builder of Things
Sometimes I build stuff other than software and this is a post about that. My wife and I had to postpone our honeymoon for a couple years due to COVID. Last spring we were able to take a trip to Thailand and really enjoyed it. So much so that when we got back we had … Continue reading Builder of Things
Sometimes I build stuff other than software and this is a post about that.
My wife and I had to postpone our honeymoon for a couple years due to COVID. Last spring we were able to take a trip to Thailand and really enjoyed it. So much so that when we got back we had a desire recreate that sort of relaxed urban yet tropical feel we enjoyed so much in various cities.
We don’t have a lot of extra space at our house but we did have some in the back which was vacated by recently fell Elm which were diseased.
I’m not one to shy away from projects I’ve never done before so why not build a deck and pergola to fill out that space for entertaining and hacking?
The first step was to even the grade. When we bought the house it was already sloped but the grinding of Elm tree trunks added another layer on top of that.
That is a lot of work but to make something 8’×20′ we need to clear a lot more than this. Only to be made worse by root after root of dead Elm tree remnants. Pick axe and sweat.
That’s more like it.
We don’t have much of a frost line here so you don’t need to do the whole concrete-pylon thing for the deck and integrated pergola. But what we do need to do is ensure that we have a retaining wall to keep wet ground from touching the cedar for the deck.
The 2×4 cedar topper is mostly just there to match what will be the cedar floor of the deck.
A bunch of gravel of various grades under the cinders create something stable that drains water beneath the cedar 4×4 which will be our columns.
This is built as two 8’×10′ sections which are connected. That makes the math much easier in my head but also easier to source good wood. Above you see the rim and floor joists for the first side with the blocking yet to be done.
I lucked out that the cedar supplier gave me 12′ 4×4s instead of the requested 10′. That gave me 2′ extra to use when framing without having to first get the whole 10′ columns leveled. Later one we’ll take them out one-by-one and replace them with the columns.
Now we have the columns in place and the whole thing leveled. Blocking has started and will get completed before adding the floor boards. I ended up using screws at an angle from the rounded corners of the ceder floor boards using “camo hidden fasteners”. After seeing how they handled the winter that was definitely the right decision.
Thankfully I had help from my wife and emeritus GNOMie Cosimo with all this.
Now we have all the floor boards on. The cedar appearance board is tacked on the edge of the rim joist to hide the pressure treated lumber. The beams have been connected at the top of the columns. The start of a privacy wall is in place to see how it will fit together. Next up, all those rafters which I used some simple angle cuts and a multi-tool to extract pockets to interference-fit over the beams.
Lastly my wife did her design magic after gathering all the outdoor furniture together.
This year I have jasmine and honeysuckle doing it’s thing to hopefully start getting some of this pergola covered with leaves and flowers by summer. I also extended the privacy wall a bit more since this picture to have a lattice for the vines to climb.
That’s it!
2024-04-19T01:32:35Z2024-04-19T01:32:35Zchergerthttps://blogs.gnome.org/chergertDetails of Christian's work on GNOMEHappenings in GNOME2024-04-24T22:14:01Zhttps://thisweek.gnome.org/posts/2024/04/twig-144/#144 Better Printing
Update on what happened across the GNOME project in the week from April 12 to April 19.
Matt prepared his talk “Modernizing Accessibility for Desktop Linux” he gave at Open Source Summit North American in Seattle. Slides available and the recording should be published soon, we will make sure to twig it.
libadwaita now has AdwButtonRow, implementing another missing pattern for boxed lists. Additionally, there’s a .boxed-list-separate style class now, that has each row in its own card with spacing between them, and AdwPreferencesGroup:separate-rows to toggle it for preferences groups
Software
Lets you install and update applications and system extensions.
The biggest update is a UI refresh: Gaphor’s UI now better follows the Adwaita style (feedback is welcome). The Property editor has be revised, so it can be used both from diagrams and the model browser. You can read the full list of changes in our ChangeLog. Builds for Windows, macOS and Linux Flatpak are available from the website and FlatHub.
Energy usage has been improved by using a more efficient method to get the time and by making use of the magic GtkWindow.suspended property to stop updating the clock when the window is not visible.
Better support for round clocks. The new GTK renderer fixed the visual glitch on transparent corners caused by large border radius. Retro now restores window dimensions and disables the border radius on maximize to make it look good, no matter the shape.
Controls have been moved to a floating header bar to stay out of the way and prevent interference with customizations.
Mahjongg
A solitaire version of the classic Eastern tile game.
Mahjongg 3.40.1 has been released, and is available on Flathub.
This release fixes a few regressions in the GTK 4 port. Most notably, the game no longer freezes after finishing a round, and the tile layout can be changed when using a language other than English.
I will also maintain Mahjongg from now on. If you want to help out with development, e.g. replace deprecated widgets, feel free to submit a MR on GitLab.
Account recovery, introduced during this cycle, could lead to an unclear situation where it was still incomplete even after successfully going through the process. We added some explanations on how to solve this. Thanks to anyone who tried it in the beta and provided us with feedback!
After fixing a focus issue upstream in GtkListView, we got rid of more focus issues in our widgets. That should make the room history completely accessible with keyboard navigation.
Third party verification, that happens in a direct chat, was partly broken as the banner about an ongoing verification was not showing up anymore. The culprit was found and we took that opportunity to improve the security instructions. Along with this bugfix, a coat of polish has been applied.
As usual, this release includes other improvements, fixes and new translations thanks to all our contributors, and our upstream projects.
Flatseal 2.2.0 is out. This new release comes with refined visuals, navigation and adaptive behavior, much more streamlined with the latest GNOME release. It also comes with bug fixes for edge cases involving global overrides and Greek translation by Athanasios Karachalios.
The PyGObject Documentation now has a new place at https://pygobject.gnome.org. This URL is easier to remember (and discover). Over time we also want to bring API docs and user guides/tutorials to this site, so we have one central place for everything Python.
The GNOME API docs for Python over at https://amolenaar.pages.gitlab.gnome.org/pygobject-docs/ have had a revamp over the past week. Thanks to Rafael Mardojai CM, property names are now properly presented. Properties and signals are also cross-referenced in the docs. Method signatures have been improved, based on the latest version of the pygobject-stubs project.
That’s all for this week!
See you next week, and be sure to stop by #thisweek:gnome.org with updates on your own projects!
2024-04-19T00:00:00Z2024-04-19T00:00:00Zhttps://thisweek.gnome.org/author/felix/Felix HäckerRecent content in Felix on This Week in GNOMEFelix on This Week in GNOME2024-04-26T00:00:00Zhttps://foundation.gnome.org/?p=18775Call for GUADEC 2025 Location ProposalsThe GNOME Foundation invites bids for hosting GUADEC 2025. For next year’s annual gathering of GNOME users and developers, we’re looking for location proposals from anywhere in the world. This is your chance to bring GUADEC to your city! If you are interested in submitting a proposal to host GUADEC 2025 in your city, please […]
The GNOME Foundation invites bids for hosting GUADEC 2025. For next year’s annual gathering of GNOME users and developers, we’re looking for location proposals from anywhere in the world. This is your chance to bring GUADEC to your city!
If you are interested in submitting a proposal to host GUADEC 2025 in your city, please submit an intention to bid by filling out this short form. Intent to Bid submissions are due by end-of-day May 3, 2024.
Final proposals should be submitted using our online form and are due by May 31, 2024.
Be prepared to include the following details in your proposal:
Location information
A list of local team members
Information about local support (GNOME or open source communities, universities, government or businesses affiliated with GNOME or open source)
Ideas about local sponsors
Venue information
Proposed dates
Travel information (local airports, trains, etc.)
Local transportation (how will attendees get around the city)
Accommodation and dining options
Social event options
Group activity options
Estimated costs and budget for hosting in this location
Deadlines Intention to bid: May 3, 2024 Final proposal submission: May 31, 2024
Proposals from previous years are available for reference and you can talk to the Foundation Board and previous GUADEC organizers to find out more about what is involved. If you need more time to finalize your bid please contact kprogri@gnome.org.
Organizing GUADEC is a large undertaking but local teams will have help from Foundation Staff members and Engagement Team contributors!
2024-04-18T17:38:21Z2024-04-18T17:38:21Zchenriksenhttps://foundation.gnome.orghttps://foundation.gnome.org/wp-content/uploads/sites/12/2020/08/cropped-icon-32x32.jpgBuilding a diverse and sustainable free software ecosystemNews – The GNOME Foundation2024-04-18T17:38:23Ztag:blogger.com,1999:blog-6112936277054198647.post-6156149132305853287udev-hid-bpf: quickstart tooling to fix your HID devices with eBPF
For the last few months, Benjamin Tissoires and I have been working on and polishing a little tool called udev-hid-bpf [1]. This is the scaffolding required quickly and easily write, test and eventually fix your HID input devices (mouse, keyboard, etc.) via a BPF program instead of a full-blown custom kernel driver or a semi-full-blown kernel patch. To understand how it works, you need to know two things: HID and BPF [2].
Why BPF for HID?
HID is the Human Interface Device standard and the most common way input devices communicate with the host (HID over USB, HID over Bluetooth, etc.). It has two core components: the "report descriptor" and "reports", both of which are byte arrays. The report descriptor is a fixed burnt-in-ROM byte array that (in rather convoluted terms) tells us what we'll find in the reports. Things like "bits 16 through to 24 is the delta x coordinate" or "bit 5 is the binary button state for button 3 in degrees celcius". The reports themselves are sent at (usually) regular intervals and contain the data in the described format, as the devices perceives reality. If you're interested in more details, see Understanding HID report descriptors.
BPF or more correctly eBPF is a Linux kernel technology to write programs in a subset of C, compile it and load it into the kernel. The magic thing here is that the kernel will verify it, so once loaded, the program is "safe". And because it's safe it can be run in kernel space which means it's fast. eBPF was originally written for network packet filters but as of kernel v6.3 and thanks to Benjamin, we have BPF in the HID subsystem. HID actually lends itself really well to BPF because, well, we have a byte array and to fix our devices we need to do complicated things like "toggle that bit to zero" or "swap those two values".
If we want to fix our devices we usually need to do one of two things: fix the report descriptor to enable/disable/change some of the values the device pretends to support. For example, we can say we support 5 buttons instead of the supposed 8. Or we need to fix the report by e.g. inverting the y value for the device. This can be done in a custom kernel driver but a HID BPF program is quite a lot more convenient.
HID-BPF programs
For illustration purposes, here's the example program to flip the y coordinate. HID BPF programs are usually device specific, we need to know that the e.g. the y coordinate is 16 bits and sits in bytes 3 and 4 (little endian):
That's it. HID-BPF is invoked before the kernel handles the HID report/report descriptor so to the kernel the modified report looks as if it came from the device.
As said above, this is device specific because where the coordinates is in the report depends on the device (the report descriptor will tell us). In this example we want to ensure the BPF program is only loaded for our device (vid/pid of 04d9/a09f), and for extra safety we also double-check that the report descriptor matches.
// The bpf.o will only be loaded for devices in this list
HID_BPF_CONFIG(
HID_DEVICE(BUS_USB, HID_GROUP_GENERIC, 0x04D9, 0xA09F)
);
SEC("syscall")
int probe(struct hid_bpf_probe_args *ctx)
{
/*
* The device exports 3 interfaces.
* The mouse interface has a report descriptor of length 71.
* So if report descriptor size is not 71, mark as -EINVAL
*/
ctx->retval = ctx->rdesc_size != 71;
if (ctx->retval)
ctx->retval = -EINVAL;
return 0;
}
Obviously the check in probe() can be as complicated as you want.
This is pretty much it, the full working program only has a few extra includes and boilerplate. So it mostly comes down to compiling and running it, and this is where udev-hid-bpf comes in.
udev-hid-bpf as loader
udev-hid-bpf is a tool to make the development and testing of HID BPF programs simple, and collect HID BPF programs. You basically run meson compile and meson install and voila, whatever BPF program applies to your devices will be auto-loaded next time you plug those in. If you just want to test a single bpf.o file you can udev-hid-bpf install /path/to/foo.bpf.o and it will install the required udev rule for it to get loaded whenever the device is plugged in. If you don't know how to compile, you can grab a tarball from our CI and test the pre-compiled bpf.o. Hooray, even simpler.
udev-hid-bpf is written in Rust but you don't need to know Rust, it's just the scaffolding. The BPF programs are all in C. Rust just gives us a relatively easy way to provide a static binary that will work on most tester's machines.
The documentation for udev-hid-bpf is here. So if you have a device that needs a hardware quirk or just has an annoying behaviour that you always wanted to fix, well, now's the time. Fixing your device has never been easier! [3].
[1] Yes, the name is meh but you're welcome to come up with a better one and go back in time to suggest it a few months ago.
[2] Because I'm lazy the terms eBPF and BPF will be used interchangeably in this article. Because the difference doesn't really matter in this context, it's all eBPF anyway but nobody has the time to type that extra "e".
[3] Citation needed
We first introduced support for dmabufs and graphics offload last fall, and it is included in GTK 4.14. Since then, some improvements have happened, so it is time for an update. Improvements down the stack The GStreamer 1.24 release has improved support for explicit modifiers, and the GStreamer media backend in GTK has been updated … Continue reading "Graphics offload revisited"
We first introduced support for dmabufs and graphics offload last fall, and it is included in GTK 4.14. Since then, some improvements have happened, so it is time for an update.
Improvements down the stack
The GStreamer 1.24 release has improved support for explicit modifiers, and the GStreamer media backend in GTK has been updated to request dmabufs from GStreamer.
Another thing that happens on the GStreamer side is that dmabufs sometimes come with padding: in that case GStreamer will give us a buffer with a viewport and expect us to only show that part of the buffer. This is sometimes necessary to accommodate stride and size requirements of hardware decoders.
GTK 4.14 supports this when offloading, and only shows the part of the dmabuf indicated by the viewport.
Improvements inside GTK
We’ve merged new GSK renderers for GTK 4.14. The new renderers support dmabufs in the same way as the old gl renderer. In addition, the new Vulkan renderer produces dmabufs when rendering to a texture.
In GTK 4.16, the GtkGLArea widget will also provide dmabuf textures if it can, so you can put it in a GtkGraphicsOffload widget to send its output directly to the compositor.
You can see this in action in the shadertoy demo in gtk4-demo in git main.
Shadertoy demo with golden outline around offloaded graphics
Improved compositor interaction
One nice thing about graphics offload is that the compositor may be able to pass the dmabuf to the KMS apis of the kernel without any extra copies or compositing. This is known as direct scanout and it helps reduce power consumption since large parts of the GPU aren’t used.
The compositor can only do this if the dmabuf is attached to a fullscreen surface and has the right dimensions to cover it fully. If it does not cover it fully, the compositor needs some assurance that it is ok to leave the outside parts black.
One way for clients to provide that assurance is to attach a specially constructed black buffer to a surface below the one that has the dmabuf attached. GSK will do this now if it finds black color node in the rendernode tree, and the GtkGraphicsOffload widget will put that color there if you set the “black-background” property. This should greatly increase the chances that you can enjoy the benefits of direct scanout when playing fullscreen video.
Offloaded content with fullscreen black background
In implementing this for GTK 4.16, we found some issues with mutter’s support for single-pixel buffers, but these have been fixed quickly.
To see graphics offload and direct scanout in action in a GTK4 video player, you can try the Light Video Player.
If you want to find out if graphics offload works on your system or debug why it doesn’t, this recent post by Benjamin is very helpful.
Summary
GTK 4 continues to improve for efficient video playback and drives improvements in this area up and down the stack.
A big thank you for pushing all of this forward goes to Robert Mader.
2024-04-17T17:39:31Z2024-04-17T17:39:31Zmclasenhttps://blog.gtk.orgAll things GTKmclasen – GTK Development Blog2024-04-17T17:43:54Ztag:blogger.com,1999:blog-5968355124473522212.post-3621800650666567368CapyPDF 0.10.0 is out
Perhaps the most interesting feature is that this new version reduces the number of external dependencies by almost 15%. In other words the number of deps went from 7 to 6. This is due to Apple Clang finally shipping with std::format support so fmt::format could be removed. The actual change was pretty much a search & replace from fmt::format to std::format. Nice.
Other features include:
L*a*b* color support in paint operations
Reworked raster image APIs
Kerned text support
Support for all PDF/X versions, not just 3
Better outline support
But most importantly, there are now stickers:
Sadly you can't actually buy them anywhere, they can only be obtained by meeting me in person and asking for one.
2024-04-17T16:04:00Z2024-04-17T16:04:00ZJussinoreply@blogger.comhttp://www.blogger.com/profile/03370287682352908292tag:blogger.com,1999:blog-5968355124473522212Jussinoreply@blogger.comhttp://www.blogger.com/profile/03370287682352908292A gathering of development thoughts of Jussi Pakkanen. Some of you may know him as the creator of the Meson build system. jpakkane at gmail dot comNibble Stew2024-04-22T10:26:11Zhttp://samthursfield.wordpress.com/?p=2408Status update, 17/04/2024
In which I meet QA testers, bang my head against the GNOME OS initial setup process, and travel overland from Scotland to Spain in 48 hours. Linux QA meetup Several companies and communities work on QA testing for Linux distros, and we mostly don’t talk to each other. GUADEC 2023 was a rare occasion where … Continue reading Status update, 17/04/2024
In which I meet QA testers, bang my head against the GNOME OS initial setup process, and travel overland from Scotland to Spain in 48 hours.
Linux QA meetup
Several companies and communities work on QA testing for Linux distros, and we mostly don’t talk to each other. GUADEC 2023 was a rare occasion where several of us were physically collocated for a short time, and a few folk proposed a “GNOME + openQA hackfest” to try and consolidate what we’re all working on.
Over time, we realized ongoing lines of communication are more useful than an expensive one-off meetup, and the idea turned into a recurring monthly call. This month we finally held the first call. In terms of connecting different teams it was a success – we had folk from Canonical/Ubuntu, Codethink, Debian, GNOME, Red Hat/Fedora and SUSE, and there are some additional people already interested in the next one. Everyone who attended this round is using openQA and we will to use the openqa:opensuse.org chat to organise future events – but the call is not specific to openQA, nor to GNOME: anything Linux-related and QA-related is in scope.
If you want to be involved in the next one, make sure you’re in the openQA chat room, or follow this thread on GNOME Discourse. The schedule is documented here and the next call should be 08:00UTC on Thursday 2nd May.
GNOME OS tests
On the topic of QA, the testsuite for GNOME OS is feeling pretty unloved at the moment. Tests still don’t pass reliably and haven’t done for months. Besides the existing issue with initial setup where GNOME Shell doesn’t start, there is a new regression that breaks the systemd user session and causes missing sound devices. Investigating these issues is a slow and boring process which you can read about in great detail on the linked issues.
Fun fact: most of GNOME OS works fine without a systemd user session – there is still a D-Bus session bus after all; systemd user sessions are quite new and we still (mostly) support non-systemd setups.
One thing is clear, we still need a lot of work on tooling and docs around GNOME OS and the tests, if we hope to get more people involved. I’m trying my best in the odd hours I have available, greatly helped by Valentin David and other folk in the #GNOME OS channel, but it still feels like wading through treacle.
We particularly could do with documentation on how the early boot and initial setup process is intended to work – its very hard to visualize just from looking at systemd unit files. Or maybe systemd itself can generate a graph of what should be happening.
Magic in the ssam_openqa tool
Debugging OS boot failures isn’t my favourite thing. I just want reliable tests. Writing support tooling in Rust is fun though, and it feels like magic to be able to control and debug VMs from a simple CLI tool, and play with them over VNC while the test suite runs.
Using a VNC connection to run shell commands is annoying at times: it’s a terminal in a desktop in a VNC viewer, with plenty of rendering glitches, and no copy/paste integration with the host. I recently noticed that while openQA tests are running, a virtio terminal is exposed on the host as a pair of in/out FIFOs, and you can control this terminal using cat and echo. This feels like actual magic.
I added a new option to ssam_openqa, available whenever the test runner is paused, to open a terminal connection to this virtio console, and now I can debug directly from the terminal on my host. I learned a few things about line buffering and terminal control codes along the way. (I didn’t get ANSI control codes like cursor movement to work, yet – not sure if my code is sending them wrong, or some TERM config is needed on the VM side. – but with backspace, tab and enter working it’s already fairly usable).
Here’s a quick demo of the feature:
Available in the 1.2.0-rc1 release. Happy debugging!
Cross country travel
Most of this month I was on holiday. If you’re a fan of overland travel, how about this: Aberdeen to Santiago in 48 hours; via night train to Crewe, camper van to Plymouth, ferry to Santander and then more driving across to Galicia. A fun trip, although I got pretty seasick on the boat until I’d had a good nights sleep. (This wasn’t a particularly low-carbon trip though despite going overland, as the train, ferry and van are all powered by big diesel engines.)
And now back to regular work – “Moving files from one machine to another using Python and YAML”, etc.
2024-04-17T13:41:37Z2024-04-17T13:41:37ZSam Thursfieldhttps://samthursfield.wordpress.comhttps://samthursfield.files.wordpress.com/2020/10/cropped-favicon.png?w=32Software and technology from Galicia, SpainSam Thursfield2024-04-17T13:41:37Zhttps://olea.org/diario/2024/04/17/Wikimedia_update.htmlLast activity in Wikimedia
Just a little update about my activity around the Wikimedia Movement.
Also, I’ve sent two poster proposals for Wikimania 2024:
Towards a Very Small GLAM entities solution:
This proposal proposes an activity line for empowering very small GLAM entities with limited resources to preserve and document cultural heritage effectively. It comprises:
the development an open-source GLAM suite and
recommendations on affordable, reliable hardware.
The suite includes:
software such as unRAID OS with ZFS for data preservation and
Wikibase and packaged software services.
Also a preload of metadata for museology (ontologies and vocabularies) and a technical information collection in the form of linked open data and documents.
The proposal outlines the project’s timeline, funding sources, and physical and online community involvement.
and
Wikimedia LEADS a Learning Ecosystem and Ameliorating Data Space:
To create a free ecosystem and data-space for learning in the Wikimedia Movement. Ecosystem will extends the Movement with new classes of knowledge and addressing sustainability needs. With:
libraries of:
practices, modeled in Wikibase as Linked Open Data (LOD);
credentials, also modeled as LOD, based in ELM;
software extensions and services required for a working implementation in the Movement.
First will address the GLAM Wiki domain, producing incremental results ready to be adopted. This domain strongly intersects with the Wikimedia Movement.
Furthermore, the methodologies, tools and many of the specific contents will be applicable to any other knowledge areas.
We have coined the term Very Small GLAM to refer the community of very small GLAM institutions: private, public, formal or informal, etc. It has not a rigorous definition, but you can think in teams of less than 10 members and reduced budget. So we’ll drop the bombastic term of «Small GLAM SLAM».
About Wikimedia LEADS, this is a new line of work also based in Wikibase to develop a Wikimedia ecosystem of models for Essence practices and microcredentials. It has been proposed for an European Union grant so it has no funding yet. This initiative interesects with Very Small GLAM as both focuses first in contents for the GLAM Wiki domain, as project driver.
2024-04-16T22:00:00Z2024-04-16T22:00:00Zhttps://olea.org/Ismael OleaPastoreando procomunes desde 1994 — Shepherding the commons since 1994
- just the English postsIsmael Olea — web personal2024-04-26T18:44:00Ztag:base-art.net,2024-04-16:/Articles/from-webkitgstreamer-to-rust-av-a-journey-on-our-stacks-layers/From WebKit/GStreamer to rust-av, a journey on our stack’s layers
In this post I’ll try to document the journey starting from a WebKit issue and
ending up improving third-party projects that WebKitGTK and WPEWebKit depend on.
I’ve been working on WebKit’s GStreamer backends for a while. Usually some new
feature needed on WebKit side would trigger work …
In this post I’ll try to document the journey starting from a WebKit issue and
ending up improving third-party projects that WebKitGTK and WPEWebKit depend on.
I’ve been working on WebKit’s GStreamer backends for a while. Usually some new
feature needed on WebKit side would trigger work on GStreamer. That’s quite
common and healthy actually, by improving GStreamer (bug fixes or implementing
new features) we make the whole stack stronger (hopefully). It’s not hard to
imagine other web-engines, such as Servo for instance, leveraging fixes made in
GStreamer in the context of WebKit use-cases.
Sometimes though we have to go deeper and this is what this post is about!
Since version 2.44, WebKitGTK and WPEWebKit ship with a
WebCodecs
backend. That backend leverages the wide range of GStreamer audio and video
decoders/encoders to give low-level access to encoded (or decoded) audio/video
frames to Web developers. I delivered a lightning
talk at
gst-conf 2023 about this topic.
There are still some issues to fix regarding performance and some W3C web
platform tests are still failing. The AV1 decoding tests were flagged early on
while I was working on WebCodecs, I didn’t have time back then to investigate
the failures further, but a couple weeks ago I went back to those specific issues.
The WebKit layout tests harness is executed by various post-commit bots, on
various platforms. The WebKitGTK and WPEWebKit bots run on Linux. The WebCodec
tests for AV1 currently make use of the GStreamer av1enc and
dav1ddec elements. We
currently don’t run the tests using the modern and hardware-accelerated
vaav1enc and vaav1dec elements because the bots don’t have compatible GPUs.
The decoding tests were failing, this
one
for instance (the ?av1 variant). In that test both encoding and decoding are
tested, but decoding was failing, for a couple reasons. Rabbit hole starts here.
After debugging this for a while, it was clear that the colorspace information
was lost between the encoded chunks and the decoded frames. The decoded video
frames didn’t have the expected colorimetry values.
The
VideoDecoderGStreamer
class basically takes encoded chunks and notifies decoded
VideoFrameGStreamer
objects to the upper layers (JS) in WebCore. A video frame is basically a
GstSample (Buffer and Caps) and we have code in place to interpret the
colorimetry parameters exposed in the sample caps and translate those to the
various WebCore equivalents. So far so good, but the caps set on the dav1ddec
elements didn’t have those informations! I thought the dav1ddec element could
be fixed, “shouldn’t be that hard” and I knew that code because I wrote it in
2018 :)
So let’s fix the GStreamer dav1ddec element. It’s a video decoder written in
Rust, relying on the dav1d-rs bindings of
the popular C libdav1d library. The dav1ddec element basically feeds encoded
chunks of data to dav1d using the dav1d-rs bindings. In return, the bindings
provide the decoded frames using a Dav1dPicture Rust structure and the
dav1ddec GStreamer element basically makes buffers and caps out of this
decoded picture. The dav1d-rs bindings are quite minimal, we implemented API on
a per-need basis so far, so it wasn’t very surprising that… colorimetry
information for decoded pictures was not exposed! Rabbit hole goes one level deeper.
So let’s add colorimetry API in dav1d-rs. When working on (Rust) bindings of a
C library, if you need to expose additional API the answer is quite often in the
C headers of the library. Every Dav1dPicture has a Dav1dSequenceHeader, in
which we can see a few interesting fields:
typedefstructDav1dSequenceHeader{...enumDav1dColorPrimariespri;///< color primaries (av1)enumDav1dTransferCharacteristicstrc;///< transfer characteristics (av1)enumDav1dMatrixCoefficientsmtrx;///< matrix coefficients (av1)enumDav1dChromaSamplePositionchr;///< chroma sample position (av1)...uint8_tcolor_range;......}Dav1dSequenceHeader;
After sharing a naive branch with rust-av co-maintainers Luca
Barbato and Sebastian
Dröge, I came up with a
couplepull-requests that eventually
were shipped in version 0.10.3 of dav1d-rs. I won’t deny matching primaries,
transfer, matrix and chroma-site enum values to rust-av‘s Pixel enum was a bit
challenging :P Anyway, with dav1d-rs fixed up, rabbit hole level goes up one
level :)
Now with the needed dav1d-rsAPI, the GStreamer dav1ddec element could be
fixed. Again, matching the various enum values to their GStreamer equivalent was
an interesting exercise. The merge
request
was merged, but to this date it’s not shipped in a stable gst-plugins-rs release
yet. There’s one more complication here, ABI broke between dav1d 1.2 and 1.4
versions. The dav1d-rs 0.10.3 release expects the latter. I’m not sure how we
will cope with that in terms of gst-plugins-rs release versioning…
Anyway, WebKit’s runtime environment can be adapted to ship dav1d 1.4 and
development version of the dav1ddec element, which is what was done in this
pull request. The rabbit is
getting out of his hole.
The WebCodec AV1 tests were finally fixed in WebKit, by this pull
request. Beyond colorimetry
handling a few more fixes were needed, but luckily those didn’t require any
fixes outside of WebKit.
Wrapping up, if you’re still reading this post, I thank you for your patience.
Working on inter-connected projects can look a bit daunting at times, but
eventually the whole ecosystem benefits from cross-project collaborations like
this one. Thanks to Luca and Sebastian for the help and reviews in dav1d-rs
and the dav1ddec element. Thanks to my fellow Igalia
colleagues for the WebKit reviews.
2024-04-16T20:15:00Z2024-04-16T20:15:00ZPhilippe Normandhttps://base-art.net/Base-Art - Philippe Normand2024-04-16T20:15:00Zhttp://blog.sonny.re/retro-v2Retro v2<![CDATA[
Retro; the customizable clock widget is now available on Flathub in v2
a href='https://flathub.org/apps/re.sonny.Retro'img width='240' alt='Download on Flathub' src='https://flathub.org/api/badge?locale=en'//a
This new release comes with
Support both 12h and 24h clock format. It follows GNOME Date & Time preference while being sandboxed thanks to libportal new API for the settings portal.
Energy usage has been improved by using a more efficient method to get the time and by making use of the magic GtkWindow.suspended property to stop updating the clock when the window is not visible.
Better support for round clocks. The new GTK renderer fixed the visual glitch on transparent corners caused by large border radius. Retro now restores window dimensions and disables the border radius on maximize to make it look good, no matter the shape.
Controls have been moved to a floating header bar to stay out of the way and prevent interference with customizations.
There are further improvements to do, but I decided to publish early because Retro was using GNOME 43 runtime which is end-of-life and I have limited time to spend on it.
Help welcome https://github.com/sonnyp/Retro/issues]]>
Retro; the customizable clock widget is now available on Flathub in v2
Energy usage has been improved by using a more efficient method to get the time and by making use of the magic GtkWindow.suspended property to stop updating the clock when the window is not visible.
Better support for round clocks. The new GTK renderer fixed the visual glitch on transparent corners caused by large border radius. Retro now restores window dimensions and disables the border radius on maximize to make it look good, no matter the shape.
Controls have been moved to a floating header bar to stay out of the way and prevent interference with customizations.
There are further improvements to do, but I decided to publish early because Retro was using GNOME 43 runtime which is end-of-life and I have limited time to spend on it.
2024-04-16T11:36:55Z2024-04-16T11:36:55Zhttp://blog.sonny.re/https://i.snap.as/W5pFkgq1.jpgSonny PiersSonny's2024-04-27T10:03:33Zhttps://blogs.gnome.org/otte/?p=6916Making GTK graphics offloading work(I need to put that somewhere because people ask about it and having a little post to explain it is nice.) What’s it about? GTK recently introduced the ability to offload graphics rendering, but it needs rather recent everything to work well for offloading video decoding. So, what do you need to make sure this […]
(I need to put that somewhere because people ask about it and having a little post to explain it is nice.)
First, you of course need a video to test. On a modern desktop computer, you want a 4k 60fps video or better to have something that pushes your CPU to the limits so you know when it doesn’t work. Of course, the recommendation has to be Big Buck Bunny at the highest of qualities – be aware that the most excellent 4000×2250 @ 60fps encoding is 850MB. On my Intel TigerLake, that occasionally drops frames when I play that with software decoding, and I can definitely hear the fan turn on.
When selecting a video file, keep in mind that the format matters.
Second, you need hardware decoding. That is provided by libva and can be queried using the vainfo tool (which comes in the `libva-utils` package in Fedora). If that prints a long list of formats (it’s about 40 for me), you’re good. If it doesn’t, you’ll need to go hunt for the drivers – due to the patent madness surrounding video formats that may be more complicated than you wish. For example, on my Intel laptop on Fedora, I need the intel-media-driver package which is hidden in the nonfree RPMFusion repository.
If you look at the list from vainfo, the format names give some hints – usually VP9 and MPEG2 exist. H264 and HEVC aka H265 are the patent madness, and recent GPUs can sometimes do AV1. The Big Buck Bunny video from above is H264, so if you’re following along, make sure that works.
Now you need a working video player. I’ll be using gtk4-demo (which is in the gtk4-devel-tools package, but you already have that installed of course) and its video player example because I know it works there. A shoutout goes out to livi which was the first non-demo video player to have a release that supports graphics offloading. You need GTK 4.14 and GStreamer 1.24 for this to work. At the time of writing, this is only available in Fedora rawhide, but hopefully Fedora 40 will gain the packages soon.
If you installed new packages above, now is a good time to check if GStreamer picked up all the hardware decoders. gst-inspect-1.0 va will list all the elements with libva support. If it didn’t pick up decoders for all the formats it should have (there should be a vah264dec listed for H264 if you want to decode the video above), then the easiest way to get them is to delete GStreamer’s registry cache in ~/.cache/gstreamer-1.0.
If you want to make sure GStreamer does the right thing, you can run the video player with GST_DEBUG=GST_ELEMENT_FACTORY:4. It will print out debug messages about all the elements it is creating for playback. If that includes a line for an element from the previous list (like `vah264dec` in our example) things are working. If it picks something else (like `avdec_h264` or `openh264dec`) then they are not.
Finally you need a compositor that supports YUV formats. Most compositors do – gnome-shell does since version 45 for example – but checking can’t hurt: If wayland-info (in the wayland-utils package in Fedora) lists the NV12 format, you’re good.
And now everything works.
If you have a 2nd monitor you can marvel at what goes on behind the scenes by running the video player with GDK_DEBUG=dmabuf,offload and GTK will tell you what it does for every frame, and you can see it dynamically switching between offloading or not as you fullscreen (or not), click on the controls (or not) and so on. Or you could have used it previously to see why things didn’t work.
You can also look at the top and gputop variant of your choice and you will see that the video player takes a bit of CPU to drive the video decoding engine and inform the compositor about new frames and the compositor takes a bit of CPU telling the 3D engine to composite things and send them to the monitor. With the video above it’s around 10% on my laptop for the CPU usage each and about 20% GPU usage.
And before anyone starts complaining that this is way too complicated: If you read carefully, all of this should work out of the box in the near future. This post just lists the tools to troubleshoot what went wrong while developing a fast video player.
It has finally happened! The long awaited major update of Fragments is now available, which includes many exciting new features. The most important addition is support for torrent files. It is now possible to select the files you want to download from a torrent. The files can be searched and sorted, individual files can be … Continue reading Fragments 3.0
It has finally happened! The long awaited major update of Fragments is now available, which includes many exciting new features.
The most important addition is support for torrent files. It is now possible to select the files you want to download from a torrent. The files can be searched and sorted, individual files can be opened directly from Fragments.
Further new features
Added torrents can now be searched
In addition to magnet links, *.torrent links in the clipboard are now also recognized
Prevent system from going to sleep when torrents are active
New torrents can be added via drag and drop
Automatic trashing of *.torrent files after adding them
Stop downloads when a metered network gets detected
Improvements
When controlling remote sessions, the local Transmission daemon no longer gets started
Torrents are automatically restarted if an incorrect location has been fixed
Torrents can now also be added via CLI
Clipboard toast notification is no longer displayed multiple times
Reduced CPU/resource consumption through adaptive polling interval
Improved accessibility of the user interface
Modernized user interface through the use of new Adwaita widgets
Update from Transmission 3.0.5 to 4.0.5
Thanks to Maximiliano and Tobias for once again helping with this release. As usual this release contains many other improvements, fixes and new translations thanks to all the contributors and upstream projects.
Also a big shoutout to the Transmission project, without which Fragments would not be possible, for their fantastic 4.0 release!
The new Fragments release can be downloaded and installed from Flathub:
2024-04-07T18:51:23Z2024-04-07T18:51:23Zhaeckerfelixhttps://blogs.gnome.org/haeckerfelix/feed/atom/Just another development blogFelix Häcker2024-04-07T18:51:23Zhttps://blogs.gnome.org/xjuan/?p=6265Cambalache 0.90.0 Released!
Hi, I am happy to announce a new Cambalache stable release. With the UI ported to Gtk 4 I bumped the version to 0.90 to reflect the fact we are really close to 1.0 Release Notes: Migrate main application to Gtk 4 Update widget catalogs to SDK 46 Add support for child custom fragments Add … Continue reading Cambalache 0.90.0 Released!
Hi, I am happy to announce a new Cambalache stable release.
With the UI ported to Gtk 4 I bumped the version to 0.90 to reflect the fact we are really close to 1.0
Release Notes:
Migrate main application to Gtk 4
Update widget catalogs to SDK 46
Add support for child custom fragments
Add add parent context menu action
Mark AdwSplitButton.dropdown-tooltip translatable. (Danial Behzadi)
Follow me in Mastodon @xjuan to get news related to Cambalache development.
Happy coding!
2024-04-06T20:31:36Z2024-04-06T20:31:36Zxjuanhttps://blogs.gnome.org/xjuanJust another GNOME Blogs sitear.xjuan.Blog2024-04-06T20:31:36Zhttps://jensge.org/2024/04/06/exercises-in-reversing/Exercises in ReversingAs a follow-up in spirit of reversing the USB a blood pressure monitor See Github project I was part of a project to revive a GPS receiver from the late 2000s. This is still work in process since it is still not possible to decode the actual GPS data, but we are getting there.
The code and documentation is also available at github and we’ve done a talk about the project at Easterhegg 21, which is on media.
As a follow-up in spirit of reversing the USB a blood pressure monitor
See Github project I was part of a project to
revive a GPS receiver from the late 2000s. This is still work in process since
it is still not possible to decode the actual GPS data, but we are getting there.
The code and documentation is also available at github and we’ve done a talk about the project at Easterhegg 21, which is on media.ccc.de (german only, sorry).
2024-04-06T13:27:35Z2024-04-06T13:27:35Zhttps://jensge.org/tag/english/feed/index.xmlJens GeorgRecent content in English on The adventures of fooEnglish on The adventures of foo2024-04-06T13:27:35Zhttps://bxt.rs/blog/just-how-much-faster-are-the-gnome-46-terminals/Just How Much Faster Are the GNOME 46 Terminals?
VTE (Virtual TErminal library) is the library underpinning various GNOME terminal emulators.
It provides a GTK widget that shows a terminal view, which is used in apps like GNOME Terminal, Console, Black Box, Tilix, Terminator, Ptyxis, and others.
It also powers embedded terminals in Builder and Workbench.
Over the GNOME 46 cycle, VTE has seen a lot of performance improvements.
Christian Hergert mentioned some of them in his blog posts about VTE and about his work in GNOME 46.
But how much did the performance actually improve?
What should you, the user, expect to feel after installing a fresh Fedora 40 update and launching your favorite terminal?
Let’s measure and find out!
If you don’t have time for measuring, you can skip straight to the finding out.
There is no shortage of ways to define “performance”, especially when it comes to terminal emulators.
One of the more tangible metrics is input latency.
Roughly, it describes how quickly the program reacts to your actions: how much time passes from the moment you press a key on your keyboard to the change in color of the pixels on your monitor.
Apps with low input latency feel snappy, whereas apps with high input latency can feel sluggish.
When the input latency is small-ish, you can get used to it and think it feels fine.
However, comparing lower and higher input latency together (for example, by switching between two apps and typing in both) can make it quite noticeable.
If you’ve ever heard people say they can’t go back to a 60 Hz monitor after trying out 144 Hz, that’s a similar effect (and input latency is partially responsible).
There are tools like Typometer that measure the input latency in software by detecting key press events and recording the screen to detect a change in pixel color.
This can work reasonably well but requires fiddling with your setup to make sure you’re not accidentally introducing any biases.
For example, a screen capture API may return the new pixel colors a few milliseconds before or after they are shown on the monitor, depending on the system setup, and you need to be aware of this when trying to measure something to a millisecond precision.
I’ve got something more interesting, a hardware input latency tester!
It consists of a light sensor attached to a Teensy board, which in turn is plugged into the computer via USB.
I should really get around to writing a full blog post about this latency tester, but for now, you should read this post by Tristan Hume about building a similar device.1
I used that post as a reference for building mine, but I wrote my own firmware and analysis scripts (these I am not sharing until they are less of an utter mess).
The main benefit of such a device is that it allows you to measure a full end-to-end input latency, including processing time in the kernel, the compositor, the application, and then the response time of the monitor itself.
You are measuring what you really see and feel, excluding only the keyboard firmware (since the latency tester sends key press events directly over USB).
There’s also very little extra load on the system, especially compared to using something like a screen capture API.
Here’s a gist of how it works.
The light sensor is aimed at a specific, small area on the monitor, which will be affected by the key press (in our case, a specific character cell in the terminal).
The board sends a key press over USB (for example, Space) and starts monitoring the light sensor readings.
As soon as it detects a jump in the light amount, it releases the key.
Then, it presses a second key (for example, Backspace) and waits for the light to change back.
Now we’re back to square one; the firmware waits a randomized amount (to prevent “snapping” to the monitor refresh rate) and repeats the experiment.
During all of this process, the board dumps light sensor readings over a serial port as fast as it can manage (I’m getting about 35,500 readings per second with my current board and firmware).
On the computer, I save all of this data into a file for offline analysis with Python code.
This analysis code finds the timestamp where the light starts to change, and subtracts it from the timestamp of the key press, to get one input latency measurement.
I then aggregate the measurements and plot them with seaborn.
Here’s an example of what the result looks like:
Let’s explore what you can find on this latency plot.
The small black dots represent the individual measurements.
As in, every dot shows a real amount of time that had passed between one key press and the corresponding change in light on the sensor.
There are 120 of these dots since I repeat each test 120 times.
Looking at the dots can confirm that the data is sensible.
We expect the bulk of the measurements to be spread uniformly across an interval roughly the size of one monitor repaint cycle.
This is because monitors generally repaint at a constant rate, and pressing a key at a random point in time should land us in a random point of the repaint cycle.
We get the lowest latency if the application renders a new frame in response right in time for the monitor to show it.
And we get the highest latency when the application finishes rendering a new frame just missing the monitor deadline, having to wait one extra repaint cycle for the pixel colors to change.
In the example above, the dots are spread over 7–8 ms, which is about equal to the ~6.94 ms refresh cycle of my 144 Hz monitor.
High outliers in the dots, or a larger spread, indicate lag or slowness of the application under test: some key presses are taking longer than others to process.
We do not expect to see any gaps between dot clusters.
They would usually indicate aliasing with the monitor repaint cycle, or some frame scheduling bug in the compositor.2
The box shows statistics over the individual measurements:
median (a measurement perfectly “in the middle” with half of the measurements lower and half of the measurements higher),
lowest and highest measurement,
25th and 75th percentiles (with 25% and 75% of the measurements lower than the line, respectively).
All in all, you can compare applications by their spread, then by the median latency, and also look if there are any outliers.
With all that said, we’re almost ready to look at some results.
I just need to tell you what exactly I was measuring the latency of.
What is raw Mutter, you may ask?
Well, Mutter is the compositor that GNOME Shell builds on top of.
Turns out, you can start Mutter on its own, without GNOME Shell, by switching to a different VT and running a command like mutter --display-server -- alacritty.
This gives you a very bare-bones environment that is only really meant for testing.
It is, however, quite useful for benchmarking, as it represents something close to a zero-overhead GNOME Shell ideal case.
I’m testing several terminal applications.
In the order of appearance on the plots, they are:
Alacritty: not VTE-based; serves as a baseline of sorts, because it is consistently one of the fastest terminals according to all of my prior tests.
VTE Test App: GTK 4, a test terminal that lives in the VTE repository.
GNOME Terminal: GTK 3,4 used to be the default in GNOME, and is still shipped out of the box in several distributions.
Since the intention is to compare GNOME 45 to GNOME 46, I used toolb\0x containers with Fedora 39 and Fedora 40 to install and run all terminals above, as packaged by Fedora with no extra tweaks.
I ran the terminals one by one and put their windows in the top left corner of the monitor.
The mouse cursor was outside the window for all tests.5
The first test is simple: I run cat > /dev/null to get an input field with no readline or similar processing, and then I measure how long it takes for the terminal to move its block cursor one cell to the right after pressing Space.
This is meant to test the best possible scenario for the terminal, with the least overhead.
This is what the test process looks like:
And here are the results:
Alacritty, which is our baseline, did not change from F39 to F40, as expected.
But look at the massive improvement on all of the VTE terminals!
They went from quite bad to pretty much on par with Alacritty, even the GTK 3 GNOME Terminal is very close.
The main change that caused this much improvement is likely this one by Christian that moves away from a 40 Hz VTE repaint timer to drawing every frame, synchronized with the monitor, as any self-respecting GTK widget should do.
Console has a few outliers which are maybe caused by its process tracking, but those are nothing new (they may be looked into for GNOME 47).
For the next test, I constructed a more realistic case.
I took a snapshot of my neovim setup and opened the README from Ptyxis.
I then strategically replaced a square of text with Unicode full-block characters to provide a bright “landing pad” for the light sensor.
The test consists of repeatedly pressing Ctrl+D and Ctrl+U to scroll the text buffer down and up in neovim.
The light sensor alternates between an empty line (dark) and the full-block landing pad (bright).
The neovim setup has a bunch of bells and whistles, so the terminal gets to have fun drawing the various underlines, undercurls, gutter icons, and the statusline.
This is what the test process looks like:
Here are the results:
The massive improvement is clear on this test too, and our GNOME 46 terminals are still pretty much on par with Alacritty!
Finally, let’s take a closer look at all Fedora 40 results on one plot:
This plot shows how much of a latency toll the neovim test takes compared to a simple cat, but the latency increase is similar across all terminals.
I also ran Alacritty’s vtebench suite across the same set of applications and configurations.
This is a fully automated benchmark that measures something completely different from input latency: PTY read and parsing performance.
It has also proven quite capable at finding crashes in VTE.
Here’s what vtebench’s README has to say:
This benchmark is not sufficient to get a general understanding of the performance of a terminal emulator. It lacks support for critical factors like frame rate or latency. The only factor this benchmark stresses is the speed at which a terminal reads from the PTY. If you do not understand what this means, please do not jump to any conclusions from the results of this benchmark.
The repaint duration can and does affect the results of this test, especially for terminals that read and parse PTY on the same thread as they run their repaint logic, like VTE.
This is what one of the vtebench benchmarks looks like:
And here are the results:
To avoid making this plot even busier, I drew the green arrows on only one of the benchmarks.
As you can see, other benchmarks show a similar trend.
VTE from GNOME 46 shows some welcome improvements here too, although a lot more varied, and not quite on par with Alacritty (which renders in a separate thread from reading and parsing).
These improvements likely come from the many other optimizations that happened in VTE during the GNOME 46 cycle.
Note that I omitted two benchmarks from these results: dense_cells and unicode.
They are the main stress tests of vtebench that hit the terminal really hard.
Unfortunately, VTE still struggles with them and shows a huge spread, which pushes the rest of the results down and makes the plot less readable.
Open this to see the full results if you’re curious.
VTE had a round of massive performance improvements in GNOME 46 which manifest as something you can really feel during normal terminal use.
The input latency is down to almost matching the fastest terminals, even in a non-trivial neovim setup with lots of complexity on screen.
The remaining difference, at least on these test cases, is close to negligible.
Some of it can be explained by VTE doing a bit more extra work for accessibility (enabled in GNOME Terminal and currently disabled in the GTK 4 terminals), scrollbar calculations, and other features.
If you’ve been avoiding VTE-based terminals due to sluggishness and input lag, now is the time to give them another chance.
Just make sure you’re running VTE 0.76, which includes all of this goodness.
Huge thanks to the VTE maintainers and contributors for making this a reality, and congratulations on an awesome release!
P.S. If you’re curious about Ptyxis or the behavior of GTK’s NGL vs. NVK vs. GL renderers, they all perform similarly to the F40 VTE Test App results shown above.
I did more extensive benchmarks of these a month ago, you can find them here.
As you can tell from the photo, I did not follow Tristan’s advice to make something fancier than just dangling wires. ↩︎
Just a few weeks ago some measurements I took showed a suspicious one-frame-long gap in the dots.
And guess what, it was a frame scheduling bug in my compositor, with none other than myself to blame for it.
Thankfully, it wasn’t hard to fix, and easy to verify afterward by redoing the same test. ↩︎
Your distribution may have a different idea of which terminal should be the default in its GNOME spin.
For example, Fedora still ships GNOME Terminal by default. ↩︎
GNOME Terminal is being ported to GTK 4 for GNOME 47, but in GNOME 46 it is still a GTK 3 application. ↩︎
To avoid the link-under-cursor detection logic skewing the results. ↩︎
2024-04-06T08:00:00Z2024-04-06T08:00:00Zhttps://bxt.rs/tags/planet-gnome/Ivan MolodetskikhRecent content in planet-gnome on Ivan Molodetskikh’s Webpageplanet-gnome on Ivan Molodetskikh’s Webpage2024-04-06T08:00:00Zhttps://blogs.gnome.org/hughsie/?p=9820fwupd and xz metadata
A few people (and multi-billion dollar companies!) have asked for my response to the xz backdoor. The fwupd metadata that millions of people download every day is a 9.5MB XML file — which thankfully is very compressible. This used to be compressed as gzip by the LVFS, making it a 1.6MB download for end-users, but … Continue reading fwupd and xz metadata
A few people (and multi-billion dollar companies!) have asked for my response to the xz backdoor. The fwupd metadata that millions of people download every day is a 9.5MB XML file — which thankfully is very compressible. This used to be compressed as gzip by the LVFS, making it a 1.6MB download for end-users, but in 2021 we switched to xz compression instead.
What actually happens behind the scenes is that the libxmlb library loads the optionally compressed metadata into a mmap-able binary blob, and then it gets used by fwupd to look for new updates for specific hardware. In libxmlb 0.3.3 we added support for xz as a compression format. Then fwupd 1.8.7 was released with xz support, preferring the xz format to the “legacy” gz format — as the metadata became a 1.1MB download, saving significant amounts of data from the CDN.
Then this week we learned that xz wasn’t the kind of thing we want to depend on. Out of an abundance of caution (and to be clear — my understanding is there is no fwupd or LVFS security problem of any kind) I’ve switched the LVFS to also generate zstd metadata, make libxmlb no longer hard depend on lzma and switched fwupd to prefer the zstd metadata over the xz metadata if the installed version of libjcat supports it. The zstd metadata is also ~3% smaller than xz (and faster to decompress), but the real benefit is that I now trust it a lot more than xz.
I’ll be doing new libxmlb and fwupd releases with the needed changes next week.
2024-04-03T08:39:01Z2024-04-03T08:39:01Zhughsiehttps://blogs.gnome.org/hughsieBlog about geeky stuffTechnical Blog of Richard Hughes2024-04-03T08:39:01Zhttps://blogs.gnome.org/uraeus/?p=10890Fedora Workstation 40 – what are we working on
So Fedora Workstation 40 Beta has just come out so I thought I share a bit about some of the things we are working on for Fedora Workstation currently and also major changes coming in from the community. Flatpak Flatpaks … Continue reading →
So Fedora Workstation 40 Beta has just come out so I thought I share a bit about some of the things we are working on for Fedora Workstation currently and also major changes coming in from the community.
Flatpak
Flatpaks has been a key part of our strategy for desktop applications for a while now and we are working on a multitude of things to make Flatpaks an even stronger technology going forward.
Christian Hergert is working on figuring out how applications that require system daemons will work with Flatpaks, using his own Sysprof project as the proof of concept application. The general idea here is to rely on the work that has happened in SystemD around sysext/confext/portablectl trying to figure out who we can get a system service installed from a Flatpak and the necessary bits wired up properly.
The other part of this work, figuring out how to give applications permissions that today is handled with udev rules, that is being worked on by Hubert Figuière based on earlier work by Georges Stavracas on behalf of the GNOME Foundation thanks to the sponsorship from the Sovereign Tech Fund. So hopefully we will get both of these two important issues resolved soon.
Kalev Lember is working on polishing up the Flatpak support in Foreman (and Satellite) to ensure there are good tools for managing Flatpaks when you have a fleet of systems you manage, building on the work of Stephan Bergman.
Finally Jan Horak and Jan Grulich is working hard on polishing up the experience of using Firefox from a fully sandboxed Flatpak. This work is mainly about working with the upstream community to get some needed portals over the finish line and polish up some UI issues in Firefox, like this one.
Toolbx
Toolbx, our project for handling developer containers, is picking up pace with Debarshi Ray currently working on getting full NVIDIA binary driver support for the containers. One of our main goals for Toolbx atm is making it a great tool for AI development and thus getting the NVIDIA & CUDA support squared of is critical.
Debarshi has also spent quite a lot of time cleaning up the Toolbx website, providing easier access to and updating the documentation there.
We are also moving to use the new Ptyxis (formerly Prompt) terminal application created by Christian Hergert, in Fedora Workstation 40. This both gives us a great GTK4 terminal, but we also believe we will be able to further integrate Toolbx and Ptyxis going forward, creating an even better user experience.
Nova
So as you probably know, we have been the core maintainers of the Nouveau project for years, keeping this open source upstream NVIDIA GPU driver alive. We plan on keep doing that, but the opportunities offered by the availability of the new GSP firmware for NVIDIA hardware means we should now be able to offer a full featured and performant driver. But co-hosting both the old and the new way of doing things in the same upstream kernel driver has turned out to be counter productive, so we are now looking to split the driver in two. For older pre-GSP NVIDIA hardware we will keep the old Nouveau driver around as is. For GSP based hardware we are launching a new driver called Nova.
It is important to note here that Nova is thus not a competitor to Nouveau, but a continuation of it.
The idea is that the new driver will be primarily written in Rust, based on work already done in the community, we are also evaluating if some of the existing Nouveau code should be copied into the new driver since we already spent quite a bit of time trying to integrate GSP there. Worst case scenario, if we can’t reuse code, we use the lessons learned from Nouveau with GSP to implement the support in Nova more quickly.
Contributing to this effort from our team at Red Hat is Danilo Krummrich, Dave Airlie, Lyude Paul, Abdiel Janulgue and Phillip Stanner.
Explicit Sync and VRR
Another exciting development that has been a priority for us is explicit sync, which is critical for especially the NVidia driver, but which might also provide performance improvements for other GPU architectures going forward.
So a big thank you to Michel Dänzer , Olivier Fourdan, Carlos Garnacho; and Nvidia folks, Simon Ser and the rest of community for working on this. This work has just finshed upstream so we will look at backporting it into Fedora Workstaton 40.
Another major Fedora Workstation 40 feature is experimental support for Variable Refresh Rate or VRR in GNOME Shell. The feature was mostly developed by community member Dor Askayo, but Jonas Ådahl, Michel Dänzer, Carlos Garnacho and Sebastian Wick have all contributed with code reviews and fixes. In Fedora Workstation 40 you need to enable it using the command
gsettings set org.gnome.mutter experimental-features "['variable-refresh-rate']"
PipeWire
Already covered PipeWire in my post a week ago, but to quickly summarize here too. Using PipeWire for video handling is now finally getting to the stage where it is actually happening, both Firefox and OBS Studio now comes with PipeWire support and hopefully we can also get Chromium and Chrome to start taking a serious look at merging the patches for this soon. Whats more Wim spent time fixing Firewire FFADO bugs, so hopefully for our pro-audio community users this makes their Firewire equipment fully usable and performant with PipeWire. Wim did point out when I spoke to him though that the FFADO drivers had obviously never had any other consumer than JACK, so when he tried to allow for more functionality the drivers quickly broke down, so Wim has limited the featureset of the PipeWire FFADO module to be an exact match of how these drivers where being used by JACK. If the upstream kernel maintainer is able to fix the issues found by Wim then we could look at providing a more full feature set. In Fedora Workstation 40 the de-duplication support for v4l vs libcamera devices should work as soon as we update Wireplumber to the new 0.5 release.
Another major feature landing in Fedora Workstation 40 that Jonas Ådahl and Ray Strode has spent a lot of effort on is finalizing the remote desktop support for GNOME on Wayland. So there has been support for remote connections for already logged in sessions already, but with these updates you can do the login remotely too and thus the session do not need to be started already on the remote machine. This work will also enable 3rd party solutions to do remote logins on Wayland systems, so while I am not at liberty to mention names, be on the lookout for more 3rd party Wayland remoting software becoming available this year.
This work is also important to help Anaconda with its Wayland transition as remote graphical install is an important feature there. So what you should see there is Anaconda using GNOME Kiosk mode and the GNOME remote support to handle this going forward and thus enabling Wayland native Anaconda.
HDR
Another feature we been working on for a long time is HDR, or High Dynamic Range. We wanted to do it properly and also needed to work with a wide range of partners in the industry to make this happen. So over the last year we been contributing to improve various standards around color handling and acceleration to prepare the ground, work on and contribute to key libraries needed to for instance gather the needed information from GPUs and screens. Things are coming together now and Jonas Ådahl and Sebastian Wick are now going to focus on getting Mutter HDR capable, once that work is done we are by no means finished, but it should put us close to at least be able to start running some simple usecases (like some fullscreen applications) while we work out the finer points to get great support for running SDR and HDR applications side by side for instance.
PyTorch
We want to make Fedora Workstation a great place to do AI development and testing. First step in that effort is packaging up PyTorch and making sure it can have working hardware acceleration out of the box. Tom Rix has been leading that effort on our end and you will see the first fruits of that labor in Fedora Workstation 40 where PyTorch should work with GPU acceleration on AMD hardware (ROCm) out of the box. We hope and expect to be able to provide the same for NVIDIA and Intel graphics eventually too, but this is definitely a step by step effort.
2024-03-28T18:56:33Z2024-03-28T18:56:33Zuraeushttps://blogs.gnome.org/uraeusBlog talking about Fedora, GNOME, GStreamer and related topics. Anything I write in this blog is me speaking as a member of the open source community, official Red Hat communication happens on Redhat.com. The comments are my own personal opinion.Christian F.K. Schaller2024-03-28T21:56:05Zhttps://blog.jwf.io/?p=2866Win-win for all: How to run a non-engineering Outreachy internship
This year, I am mentoring again with the Outreachy internship program. It is my third time mentoring for Outreachy and my second time with the Fedora Project. However, it is my first time mentoring as a Red Hat associate. What also makes this time different from before is that I
This year, I am mentoring again with the Outreachy internship program. It is my third time mentoring for Outreachy and my second time with the Fedora Project. However, it is my first time mentoring as a Red Hat associate. What also makes this time different from before is that I am mentoring a non-engineering project with Outreachy. Or in other words, my project does not require an applicant to write any code. Evidently, the internship description was a hook. We received an extremely large wave of applicants literally overnight. Between 40-50 new contributors arrived to the Fedora Marketing Team in the first week. Planning tasks and contributions for beginners already took effort. Scaling that planning work overnight for up to 50 people simultaneously is extraordinarily difficult.
During this round, my co-mentor Joseph Gayoso and I experimented with new approaches at handling the tsunami wave. There are two competing forces at play. One, you need to provide engagement to top performers so they remain motivated to continue. Two, you need to provide new opportunities for emerging contributors to distinguish themselves. It is easier to do one of these but hard to do both simultaneously. However, Joseph and I agreed on something important. We agreed that all applicants should end the contribution phase with something practically useful. As mentors, we asked ourselves how to prepare applicants to be successful open source contributors beyond this one month.
In this article, you will get some practical takeaways for mentoring with Outreachy. First, I will share our practical approach for structuring and planning an open source project during the Outreachy contribution phase. Second, I will detail the guiding philosophy Joseph and I follow for how we planned the contribution phase.
About Outreachy
This article assumes you already know a thing or two about the Outreachy internship program. If not, Outreachy provides internships in open source and open science. Outreachy provides internships to people subject to systemic bias and impacted by underrepresentation in the technical industry where they live. You can read more on the Outreachy website.
What makes Outreachy unique is that the internships are remote and often open without geographic or nationality constraints. Applicants from nearly every continent of the world have participated in Outreachy. Also, Outreachy is distinguished by the contribution phase. For a one-month period, approved Outreachy applicants are encouraged to participate in the project community as a contributor. Applicants spend the month learning about the project, the community, the mentors, and the work involved for the internship. This provides applicants an opportunity to grow their open source identity. It also gives mentors an opportunity to assess applicants on their skills and communication abilities.
However, this contribution phase can be intimidating as a mentor, especially if you are new to mentoring with Outreachy. A wave of people eager to contribute could suddenly appear overnight at your project’s door steps. If you are not prepared, you will have to adapt quickly!
Pre-Requisite Tasks: Raising the Outreachy bar
My co-mentor and I knew that a wave of applicants was coming. However, we didn’t expect the wave to be as big as it was. After the first week of the contribution phase, we knew we needed a better way to scale ourselves. We were limited in our person-power. The approach we took to addressing the mental overload was defining pre-requisite tasks.
We defined pre-requisite tasks as tasks that any applicant MUST complete in order to be considered eligible for our internship. Without completing these tasks, we explained that final applications would not be accepted by mentors. The defining characteristics of these pre-requisite tasks were that they were personalized, repeatable, and measurable. We came up with five pre-requisite tasks that all applicants were required to complete beyond the initial qualification for Outreachy:
Each of these tasks were personalized to each applicant. They each have a unique account profile, with their pictures, time zones, and chat system usernames. The personal blog is a personal space on the Internet for each applicant to start writing new posts. The blog post prompts encouraged applicants to start filling up their blogs with Fedora content. The social media post helped applicants promote themselves as budding open source enthusiasts in their existing web spaces.
This approach had two benefits. First, it provided clear guidance to all newcomers and early-stage applicants on how to get started with contributing to Fedora for the Outreachy internship. This took a burden off of mentors answering the same questions about getting started. It also gave new applicants something to start on right away. Joseph and I were able to put more time into reviewing incoming contributions and brainstorming new tasks.
Portfolio-driven submissions for Outreachy
Toward the third week, many applicants had completed the pre-requisite tasks and were ready for more advanced tasks. Many had already taken on advanced projects already, beyond the pre-requisite tasks. Although the pre-requisite tasks did reduce the applicant pool, there were still between 20-30 people who completed them all. Again, the approach had to adapt as our ability to keep up with new contributions slowed down.
From here, we encouraged applicants to build personal portfolio pages that described their contributions with Fedora. This encouraged applicants to use the blog they built in the previous tasks, although they are not required to use their blog to host their portfolio. The only requirement we added was that it should be publicly visible on the Internet without a paywall. So, no Google Docs. Most applicants have ended up using their blog for this purpose though.
How did a portfolio help?
Building a portfolio solved multiple challenges for our Outreachy project at once. First, the portfolios will simplify how the project mentors review final applications after the deadline on April 2nd, 2024. It will be streamlined because we will have a single place we can refer to that describes the applicant’s achievements. It gives us a quick, easily shareable place to review and share with other stakeholders.
Second, it ends up being something useful to the applicant as well. The portfolio page captures a month’s worth of contributions to open source. For many applicants, this is their first time ever interacting with an open source community online. So, it is a big deal to block out a month of time to volunteer on a project in a competitive environment for a paid, remote internship opportunity. Writing a portfolio page gives applicants the confidence to represent their contributions to Fedora, regardless of whether they are selected for the Fedora internship. It becomes a milestone marker for themselves and for their professional careers.
Our philosophy: You win, we win.
This idea of applicants building something that is useful for themselves underpins the approach that Joseph and I took on structuring our non-engineering Outreachy internship. If I had to summarize the philosophy in one sentence, it might be like this:
Everyone who participants as an Outreachy applicant to Fedora should finish the contribution phase with more than they had at the start of the contribution phase.
myself
Our philosophy can be applied to engineering and non-engineering internships. However, applying the philosophy to our non-engineering project required improvisation as we went. There are examples of design-centered Outreachy internships, but I have not seen a marketing or community manager internship before. This was a challenge because there were not great models to follow. But it also left us room to innovate and try ideas that we have never tried before.
Adopting this philosophy served as helpful guidance on planning what we directed applicants to do during the contribution phase. It allowed us to think through ways that applicants could make real, recognizable contributions to Fedora. It also enables applicants to achieve a few important outcomes:
Get real experience in a real project.
Build their own brand as open source contributors.
Gain confidence at collaborating in a community.
The contribution phase is not yet over. So, we will continue to follow this philosophy and see where it guides us into the end of this phase!
Share your Outreachy mentoring experience!
Have you experienced or seen a marketing or community manager internship in Outreachy before? Know a project or a person who has done this? Or is this totally new to you? Drop a comment below with your thoughts. Don’t forget to share with someone else if you found this advice useful.
2024-03-28T08:00:00Z2024-03-28T08:00:00ZJustin W. Floryhttps://blog.jwf.io/tag/fedora-planet/https://i0.wp.com/blog.jwf.io/wp-content/uploads/2023/08/favicon.png?fit=16%2C16&ssl=1Free & Open Source, technology, travel, and life reflectionsFedora Planet Archives – /home/jwf/2024-03-23T14:20:26Zhttps://blogs.gnome.org/alatiera/?p=5107Thoughts on employing PGO and BOLT on the GNOME stack
Christian was looking at PGO and BOLT recently I figured I’d write down my notes from the discussions we had on how we’d go about making things faster on our stack, since I don’t have time or the resource to pursue those plans myself atm. First off let’s start with the basics, PGO (profile guided … Continue reading Thoughts on employing PGO and BOLT on the GNOME stack
Christian was looking at PGO and BOLT recently I figured I’d write down my notes from the discussions we had on how we’d go about making things faster on our stack, since I don’t have time or the resource to pursue those plans myself atm.
First off let’s start with the basics, PGO (profile guided optimizations) and BOLT (Binary Optimization and Layout Tool) work in similar ways. You capture one or more “profiles” of a workload that’s representative of a usecase of your code and then the tools do their magic to make the common hot paths more efficient/cache-friendly/etc. Afterwards they produce a new binary that is hopefully faster than the old one and functionally identical so you can just replace it.
Now already we have two issues here that arise here:
First of all we don’t really have any benchmarks in our stack, let alone, ones that are rounded enough to account for the majority of usecases. Additionally we need better instrumentation to capture stats like frames, frame-times, and export them both for sysprof and so we can make the benchmark runners more useful.
Once we have the benchmarks we can use them to create the profiles for optimizations and to verify that any changes have the desired effect. We will need multiple profiles of all the different hardware/software configurations.
For example for GTK ideally we’d want to have a matrix of profiles for the different render backends (NGL/Vulkan) along with the mesa drivers they’d use depending on different hardware AMD/Intel and then also different architectures, so additional profile for Raspberrypi5 and Asahi stacks. We might also want to add a profile captured under qemu+virtio while we are it too.
Maintaining the benchmarks and profiles would be a lot of work and very tailored to each project so they would all have to live in their upstream repositories.
On the other hand, the optimization itself has to be done during the Tree/userland/OS composition and we’d have to aggregate all the profiles from all the projects to apply them. This is easily done when you are in control of the whole deployment as we can do for the GNOME Flatpak Runtime. It’s also easy to do if you are targeting an embedded deployment where most of the time you have custom images you are in full control off and know exactly the workload you will be running.
If we want distros to also apply these optimizations and for this to be done at scale, we’d have to make the whole process automatic and part of the usual compilation process so there would be no room for error during integration. The downside of this would be that we’d have a lot less opportunities for aggregating different usecases/profiles as projects would either have to own optimizations of the stack beneath them (ex: GTK being the one relinking pango) or only relink their own libraries.
To conclude, Post-linktime optimization would be a great avenue to explore as it seems to be one of the lower-hanging fruits when it comes to optimizing the whole stack. But it also would be quite the effort and require a decent amount of work to be committed to it. It would be worth it in the long run.
2024-03-26T15:42:51Z2024-03-26T15:42:51ZJordan Petridishttps://blogs.gnome.org/alatieraJust another GNOME Blogs siteRust in Peace2024-03-26T15:42:51Zhttps://wingolog.org/2024/03/26/hacking-v8-with-guix-bishacking v8 with guix, bis
Good day, hackers. Today, a pragmatic note, on hacking on V8 from a
Guix system.
I’m going to skip a lot of the background because, as it turns out, I
wrote about this already almost a decade
ago.
But following that piece, I mostly gave up on doing V8 hacking from a
Guix machine—it was more important to just go with the flow of the
ever-evolving upstream toolchain. In fact, I ended up installing Ubuntu
LTS on my main workstations for precisely this reason, which has worked
fine; I still get Guix in user-space, which is better than nothing.
Since then, though, Guix has grown to the point that it’s easier to
create an environment that can run a complicated upstream source
management project like V8’s. This is mainly guix shell
in the --container --emulate-fhs mode. This article is a step-by-step
for how to get started with V8 hacking using Guix.
get the code
You would think this would be the easy part: just git clone the V8
source. But no, the build wants a number of other Google-hosted
dependencies to be vendored into the source tree. To perform the
initial fetch for those dependencies and to keep them up to date, you
use helpers from the
depot_tools
project. You also use depot_tools to submit patches to code review.
When you live in the Guix world, you might be tempted to look into what
depot_tools actually does, and to replicate its functionality in a
more minimal, Guix-like way. Which, sure, perhaps this is a good
approach for packaging V8 or Chromium or something, but when you want
to work on V8, you need to learn some humility and just go with the
flow. (It’s hard for the kind of person that uses Guix. But it’s what
you do.)
You can make some small adaptations, though. depot_tools is mostly
written in Python, and it actually bundles its own virtualenv support
for using a specific python version. This isn’t strictly needed, so we
can set the funny environment variable VPYTHON_BYPASS="manually managed python not supported by chrome operations" to just use python from the
environment.
Sometimes depot_tools will want to run some prebuilt binaries.
Usually on Guix this is anathema—we always build from source—but there’s
only so much time in the day and the build system is not our circus, not
our monkeys. So we get Guix to set up the environment using a container
in
--emulate-fhs
mode; this lets us run third-party pre-build binaries. Note, these
binaries are indeed free software! We can run them just fine if we
trust Google, which you have to when working on V8.
no, really, get the code
Enough with the introduction. The first thing to do is to check out
depot_tools.
mkdir src
cd src
git clone https://chromium.googlesource.com/chromium/tools/depot_tools.git
I’m assuming you have git in your Guix environment already.
Then you need to initialize depot_tools. For that you run a python
script, which needs to run other binaries – so we need to make a
specific environment in which it can run. This starts with a manifest
of packages, is conventionally placed in a file named manifest.scm in
the project’s working directory, though you don’t have one yet, so you
can just write it into v8.scm or something anywhere:
Then, you guix shell -m v8.scm. But you actually do more than that,
because we need to set up a container so that we can expose a standard
/lib, /bin, and so on:
--container: This is what lets us run pre-built binaries, because
it uses Linux namespaces to remap the composed packages to /bin,
/lib, and so on.
--network: Depot tools are going to want to download things, so we
give them net access.
--share: By default, the container shares the current working
directory with the “host”. But we need not only the checkout for V8
but also the sibling checkout for depot tools (more on this in a
minute); let’s just share the whole home directory. Also, we share
the /run/user/1000 directory, which is $XDG_RUNTIME_DIR, which
lets us access the SSH agent, so we can check out over SSH.
--preserve: By default, the container gets a pruned environment.
This lets us pass some environment variables through.
--emulate-fhs: The crucial piece that lets us bridge the gap
between Guix and the world.
--manifest: Here we specify the list of packages to use when
composing the environment.
We can use short arguments to make this a bit less verbose:
I would like it if all of these arguments could somehow be optional,
that I could get a bare guix shell invocation to just apply them, when
run in this directory. Perhaps some day.
Running guix shell like this drops you into a terminal. So let’s
initialize depot tools:
cd $HOME/src
export VPYTHON_BYPASS="manually managed python not supported by chrome operations"
export PATH=$HOME/src/depot_tools:$PATH
export SSL_CERT_DIR=/etc/ssl/certs/
export SSL_CERT_FILE=/etc/ssl/certs/ca-certificates.crt
gclient
This should download a bunch of things, I don’t know what. But at this
point we’re ready to go:
fetch v8
This checks out V8, which is about 1.3 GB, and then probably about as
much again in dependencies.
build v8
You can build V8 directly:
# note caveat below!
cd v8
tools/dev/gm.py x64.release
This will build fine... and then fail to link. The precise reason is obscure to me: it would seem
that by default, V8 uses a whole Debian sysroot for Some Noble Purpose, and ends up linking against it. But it
compiles against system glibc, which seems to have replaced fcntl64
with a versioned symbol, or some such nonsense. It smells like V8 built
against a too-new glibc and then failed trying to link to an old glibc.
To fix this, you need to go into the args.gn that was generated in
out/x64.release and then add use_sysroot = false, so that it links
to system glibc instead of the downloaded one.
Then inside the container you need to set the PATH and such, so we
could put this into the V8 checkout as env:
#!/bin/sh
# Look for depot_tools in sibling directory.
depot_tools=`cd $(dirname $0)/../depot_tools && pwd`
export PATH=$depot_tools:$PATH
export VPYTHON_BYPASS="manually managed python not supported by chrome operations"
export SSL_CERT_DIR=/etc/ssl/certs/
export SSL_CERT_FILE=/etc/ssl/certs/ca-certificates.crt
exec "$@"
This way you can run ./guix-env ./env tools/dev/gm.py x64.release and
not have to “enter” the container so much.
notes
This all works fine enough, but I do have some meta-reflections.
I would prefer it if I didn’t have to use containers, for two main
reasons. One is that the resulting build artifacts have to be run in
the container, because they are dynamically linked to e.g. /lib, at
least for the ELF loader. It would be better if I could run them on the
host (with the host debugger, for example). Using Guix to make the
container is better than e.g. docker, though, because I can ensure that
the same tools are available in the guest as I use on the host. But
also, I don’t like adding “modes” to my terminals: are you in or out of
this or that environment. Being in a container is not like being in a
vanilla guix shell, and that’s annoying.
The build process uses many downloaded tools and artifacts, including
clang itself. This is a feature, in that I am using the same compiler
that colleagues at Google use, which is important. But it’s also
annoying and it would be nice if I could choose. (Having the same
clang-format though is an absolute requirement.)
There are two tests failing, in this configuration. It is somehow
related to time zones. I have no idea why, but I just ignore them.
If the build system were any weirder, I would think harder about maybe
using Docker or something like that. Colleagues point to
distrobox as being a useful
wrapper. It is annoying though, because such a docker image becomes
like a little stateful thing to do sysadmin work on, and I would like to
avoid that if I can.
Welp, that’s all for today. Hopefully if you are contemplating
installing Guix as your operating system (rather than just in
user-space), this can give you a bit more information as to what it
might mean when working on third-party projects. Happy hacking and
until next time!
2024-03-26T11:51:53Z2024-03-26T11:51:53ZAndy Wingohttps://wingolog.org/https://wingolog.org/feed/atomA mostly dorky weblog by Andy Wingowingolog2024-03-26T11:51:53Zhttps://blogs.gnome.org/jangernert/?p=250Newsflash 3.2
Another small feature update just in time for gnome 46. Subscribe via CLI Lets start with something that already went into version 3.1.4: you can subscribe to feeds via CLI now. The idea is that this is a building block for seamlessly subscribing to websites from within a browser or something similar. Lets see how … Continue reading Newsflash 3.2
Another small feature update just in time for gnome 46.
Subscribe via CLI
Lets start with something that already went into version 3.1.4: you can subscribe to feeds via CLI now. The idea is that this is a building block for seamlessly subscribing to websites from within a browser or something similar. Lets see how this develops further.
Scrap all new Articles of a Feed
If Gitlab upvotes is a valid metric, this feature was the most requested one so far. Feed settings gained a new toggle to scrap the content of new articles. The sync will complete normally and in a second operation Newsflash tries to download the full content of all new articles in the background.
This is especially useful when there is no permanent internet connection. Now you can let Newsflash sync & download content while on WiFi and read the complete articles later even without an internet connection.
Update Feed URL
The local RSS backend gained the ability to update the URL where the feed is located (see the screenshot above). Sadly none of the other services support this via their APIs as far as I know.
Clean Database
The preferences dialog gained the ability to drop all old article and “vacuum” the database right away. Depending on the size of the database file this can take a few seconds, that’s why it is not done in the background during normal operations yet.
(btw: I’m not sure if I should keep the button as “destructive-action”)
Internal Refactoring
Just a heads up that a lot of code managing the loading of the article list and keeping track of the displayed article and its state was refactored. If there are any regressions, please let me know.
Profiling
Christian Hergerts constant stream of profiling blog posts finally got to me. So I fired up sysprof. Fully expecting to not be knowledgeable enough to draw any meaningful conclusions from the data. After all, the app is pretty snappy on my machine ™, so any improvements must be hard to find and even harder to solve. But much to my surprise about 30 minutes later two absolutely noticeable low hanging fruit performance problems were discovered and fixed.
So I encourage everyone to just try profiling your code. You may be surprised what you find.
Adwaita Dialogs & Removing Configurable Shortcuts
Of course this release makes use of the new Adwaita Dialogs. For all the dialogs but one:
Configuring custom keybindings still spawns a new modal window. Multiple overlapping dialogs isn’t the greatest thing in the world. This and another annoying issue made me think about removing the feature from Newsflash completely.
The problem is that all shortcuts need to be disabled whenever the user is about to enter text. Otherwise the keybindings with a single letter cannot be entered as text.
All major feed readers (feedly, innoreader, etc) have a fixed set of cohesive keyboard shortcuts. I’ve been thinking about either having 2-3 shortcut configurations to choose from or just hard-coding keybindings all together.
I’d like to hear your thoughts. Do you use custom shortcuts? Would you be fine with a well thought out but hard-coded set of shortcuts? Would you prefer to choose from a few pre-defined shorcut configurations? Let me know, and help me find the best keybindings for all the actions that can be triggered via keyboard.
2024-03-25T22:34:49Z2024-03-25T22:34:49Zjanlukasgernerthttps://blogs.gnome.org/jangernertNews about Newsflash2024-03-25T22:34:49Zhttps://seadve.github.io/blog/10-kooha-2-3/Kooha 2.3 Released!
Kooha is a simple screen recorder for Linux with a minimal interface. You can simply click the record button without having to configure a bunch of settings.
While we strive to keep Kooha simple, we also want to make it better. This release, composed of over 300 commits, is focused on quality-of-life improvements and bug fixes.
This release includes a refined interface, improved area selection, more informative notifications, and other changes. Read on to learn more about the new features and improvements.
New Features and Improvements
Refined Interface
The main screen now has a more polished look. It now shows the selected format and FPS. This makes it easier to see the current settings at a glance, without having to open the settings window.
Other than that, progress is now shown when flushing the recording. This gives a better indication when encoding or saving is taking longer than expected.
Furthermore, the preferences window is also improved. It is now more descriptive and selecting FPS is now easier with a dropdown menu.
Improved Area Selection
The area selection window is now resizable. You can now resize the window to fit your screen better. Additionally, the previously selected area is now remembered across sessions. This means that if you close Kooha and open it again, the area you selected will be remembered. Other improvements include improved focus handling, sizing fixes, better performance, and a new style.
More Informative Notifications
Record-done notifications now show the duration and size of the recorded video. This is inspired by GNOME Shell screencast notifications.
Moreover, the notification actions now work even when the application is closed.
Other Changes
Besides the mentioned features, this release also includes:
Logout and idle are now inhibited while recording.
The audio no longer stutters and gets corrupted when recording for a long time.
The audio is now recorded in stereo instead of mono when possible.
The recordings are no longer deleted when flushing is canceled.
Incorrect output video orientation on certain compositors is now fixed.
Performance and stability are improved.
Getting Kooha 2.3
Kooha is available on Flathub. You can install it from there, and since all of our code is open-source and can be freely modified and distributed according to the license, you can also download and build it from source.
Closing Words
Thanks to everyone who has supported Kooha, be it through donations, bug reports, translations, or just using it. Your support is what keeps this project going. Enjoy the new release!
2024-03-24T04:29:00Z2024-03-24T04:29:00Zseadvehttps://seadve.github.io/atom.xmlApplication developer based in the PhilippinesSeaDve2024-03-24T04:29:00Zhttps://blogs.gnome.org/tbernard/?p=10255Mini GUADEC 2024: We have a Venue!
We’ve had a lot of questions from people planning to attend this year’s edition of the Berlin Mini GUADEC from outside Berlin about where it’s going to happen, so they can book accommodation nearby. We have two good news on that front: First, we have secured (pending a few last organizational details) a very cool … Continue reading Mini GUADEC 2024: We have a Venue!
We’ve had a lot of questions from people planning to attend this year’s edition of the Berlin Mini GUADEC from outside Berlin about where it’s going to happen, so they can book accommodation nearby. We have two good news on that front: First, we have secured (pending a few last organizational details) a very cool venue, and second: The venue has a hostel next to it, so there’s the possibility to stay very close by for cheap :)
Come join us at Regenbogenfabrik
The event will happen at Regenbogenfabrik in Kreuzberg (Lausitzerstraße 21a). The venue is a self-organized cultural center with a fascinating history, and consists of, in addition to the event space, a hostel, bike repair and woodworking workshops, and a kindergarten (lucky for us closed during the GUADEC days).
The courtyard at Regenbogenfabrik
Some of the perks of this venue:
Centrally located (a few blocks from Kottbusser Tor)
We can stay as late as we want (no being kicked out at 6pm!)
Plenty of space for hacking
Lots of restaurants, bars, and cafes nearby
Right next to the Landwehrkanal and close to Görlitzer Park
If you’re coming to Berlin from outside and would like to stay close to the venue there’s no better option than staying directly at the venue: We’ve talked to the Regebogenfabrik Hostel, and there’s still somewhere around a dozen spots available during the GUADEC days (in rooms for 2, 3, or 8 people).
Prices range between 20 and 75 Euro per person per night, depending on the size of the room. You can book using the form here (german, but Firefox Translate works well these days :) ).
As the organizing team we don’t have the capacities to get directly involved in booking the accommodations, but we’re in touch with the hostel people and can help with coordination.
Note: If you’re interested in staying at the hostel act fast, because spots are limited. To be sure to get one of the open spots, please book by next Tuesday (March 26th) and mention the codeword “GNOME” so they know to put you in rooms with other GUADEC attendees.
If you have any other questions feel free to join our Matrix room.
See you in Berlin!
2024-03-22T18:51:31Z2024-03-22T18:51:31ZTobias Bernardhttps://blogs.gnome.org/tbernardTobias Bernard's GNOME BlogSpace and Meaning2024-03-23T14:02:32Zhttp://samthursfield.wordpress.com/?p=2381Status update, 20/03/2024 – TinySPARQL and Tracker Miners
GNOME 46 just released, and with it comes TinySPARQL 3.7 (aka Tracker SPARQL) and Tracker Miners 3.7. Here’s what I’ve been involved with this month in those projects. Google Summer of Code It wasn’t my intention to prepare another internship before the last one was even finished. It seems that in GNOME we have fewer … Continue reading Status update, 20/03/2024 – TinySPARQL and Tracker Miners
GNOME 46 just released, and with it comes TinySPARQL 3.7 (aka Tracker SPARQL) and Tracker Miners 3.7. Here’s what I’ve been involved with this month in those projects.
Google Summer of Code
It wasn’t my intention to prepare another internship before the last one was even finished. It seems that in GNOME we have fewer projects and mentors than ever – only eight ideas this year, compared to fourteen confirmed projects back in 2020. So I proposed an idea for TinySPARQL, and here we are.
The idea, in brief: I’ve been working a bit with GraphQL recently, which doesn’t live up to the hype, but does have nice query frontends such as GraphQL Playground and graphiql that let you develop and test queries in realtime. This is a screenshot of graphiql:
In TinySPARQL, we have a commandline tool tracker3 sparql which can run queries and print the results. This is handy for developing testing queries independently of the app logic, but it’s only useful if you’re already something a SPARQL expert.
What if TinySPARQL had a web interface similar to the GraphQL Playground?
Besides running queries and showing the output, this could have example queries, resource browsing, as-you-type error checks, integrated documentation, and more fun things listed in this issue. My hope is this would encourage more folk to play around with the data running interesting queries and would help to visualize what you can do with a detailed metadata index for your local content. I think a lot of people see Tracker Miner FS as a black box that does basic string matching, and not the flexible database that it actually is.
Lots of schools teach HTML and JavaScript so this project seems like a great opportunity for an intern to take ownership of and show their skills. Applications are open until 2nd April, and we’ll be running a couple of online meetups later this week (Thursday 21st and/or Friday 22nd March) to help you create a good application. Join the #tracker:gnome.org Matrix room if you’re interested.
By the way, it’s only recently been possible to separate your queries from the rest of your app’s code. I wrote about this here: Standalone SPARQL Queries. The TrackerSparqlStatement class is flexible and fun and you can read your SPARQL statements straight from a GResource file. If you used libtracker-sparql around 1.x you’ll remember a horrible thing named TrackerSparqlBuilder – the query developer experience has come a long way since then.
New security features
There are some new features this cycle thanks to hard work by Carlos. I’ll let him write up the fun parts. One part that’s not much fun, is the increased security protections for tracker-extract. The background here is that tracker-extract uses many different media parsing libraries, and if any one of those libraries shipped by your distro contains a vulnerability, that could potentially be exploited by getting you to download a malicious file which would then be processed by tracker-extract.
We have no evidence that anyone’s ever actually done this. But there was a writeup on how it could happen recently using a vulnerability in a library named libcue which nobody is maintaining, including a clever bypass of the existing SECCOMP protection. Carlos did a writeup of this on his blog: On CVE-2023-43641.
With Tracker Miners 3.7, Carlos extended the existing SECCOMP sandbox to cover the entire extractor process rather than just the processing thread, which prevents that theoretical line of attack. And, he added an additional layer of sandboxing using a new kernel API called Landlock, which lets a process block itself from accessing any files except those it specifically needs.
From my perspective it’s rather draining to help maintain the sandboxing. When it works, nobody notices. When the sandboxing causes issues, we hear about it straight away. And there are plenty of issues! Even the build-time configuration for Landlock seems to need hours of debate.
SECCOMP works by denying access to any kernel APIs except those legitimately needed by the extractor process and the libraries it uses. Linux has 450+ syscalls and counting, and we maintain an explicit allowlist. Any change to GLibc, GIO, GStreamer or any media parsing library may then change what syscall gets used. If an unexpected syscall is called the tracker-extract process is killed with SIGSYS, which gets reported as a crash in just the same way as segfaults caused by programming errors.
It’s draining to support something that can break randomly by things that are out of our control. What else can we do though?
What’s next?
It might seem like openQA testing and desktop search are unrelated, but there is a clear connection.
Making reproducible integration tests for a search engine is a very hard problem. Back last decade I worked on the project’s Gitlab CI setup and “functional tests”. These tests live in the tracker-miners.git source tree, and run the real the crawler and extractor, testing that we can create a file named hello.txt, wait for it to be indexed and search for its contents. Quite a step forwards from unreproducible “works on my machine” testing that came before, but not representative of real use cases.
Real GNOME users do not have a single file in their home dir named hello.txt. Rather they have GBs or TBs of content to be indexed, and they have expectations about what constitutes the “best match” for a given search term.
I’m not interested in working to solve this kind of thing until we can build regression tests so that things don’t just work, but keep working in the long term. Hence, the work-in-progress gnome_search test for openQA, and the example-desktop-content repo. This is at the “working prototype” stage, and is now ready for some deeper thinking about what specific scenarios we want to test.
Some other things that may or may not happen next cycle in desktop search, depending on whether people care to help push them forwards:
beginning the rename: this won’t happen all at once, but we want to start calling the database TinySPARQL, and the indexer something else, still to be decided. (Ideas welcome!)
a ‘limiter’ to detect when a directory contains so much content that the indexer would burn significant CPU and IO resource trying to index everything up front (which requires corresponding UI changes so that there’s a way to “opt in” to indexing such locations on demand)
indexing the whole $HOME directory (which I personally don’t want to land without the ‘limiter’ in place, but let’s see)
One thing is certain, next month things are certainly going to slow down for me… I’m holiday for two full weeks over Easter, spring is coming and I plan to spend most of my time relaxing in a hammock. Hopefully we’ve sowed a lot of seeds this month which will soon turn into flowers.
2024-03-20T16:59:17Z2024-03-20T16:59:17ZSam Thursfieldhttps://samthursfield.wordpress.comhttps://samthursfield.files.wordpress.com/2020/10/cropped-favicon.png?w=32Software and technology from Galicia, SpainSam Thursfield2024-04-17T13:41:37Zhttps://foundation.gnome.org/?p=18704Introducing GNOME 46The GNOME Project is proud to announce the release of GNOME 46, ‘Kathmandu’. This release brings remote login with RDP, variable refresh rates (VRR), many accessibility improvements, enhanced notifications, and improved Settings. The Files app comes with a new global search and many other enhancements, and a whole slew of new apps have joined GNOME Circle. […]
The GNOME Project is proud to announce the release of GNOME 46, ‘Kathmandu’.
This release brings remote login with RDP, variable refresh rates (VRR), many accessibility improvements, enhanced notifications, and improved Settings. The Files app comes with a new global search and many other enhancements, and a whole slew of new apps have joined GNOME Circle.
To learn more about the changes in GNOME 46 you can read the release notes.
GNOME 46 will be available shortly in many distributions, such as Fedora 40 and Ubuntu 24.04. If you want to try it today, you can look for their beta releases, which will be available very soon:
We are also providing our own installer images for debugging and testing features. These images are meant for installation in a vm and require GNOME Boxes with UEFI support. We suggest getting Boxes from Flathub.
If you are interested in building applications for GNOME 46, look for the GNOME 46 Flatpak SDK, which is available in the http://www.flathub.org/ repository.
This six-month effort wouldn’t have been possible without the whole GNOME community, made of contributors and friends from all around the world: developers, designers, documentation writers, usability and accessibility specialists, translators, maintainers, students, system administrators, companies, artists, testers, the local GNOME Asia team in Nepal, and last, but not least, our users.
GNOME would not exist without all of you. Thank you to everyone!
We hope to see some of you at GUADEC 2024 in Denver, Colorado!
Our next release, GNOME 47, is planned for September 2024. Until then, enjoy GNOME 46.
2024-03-20T15:22:36Z2024-03-20T15:22:36Zchenriksenhttps://foundation.gnome.orghttps://foundation.gnome.org/wp-content/uploads/sites/12/2020/08/cropped-icon-32x32.jpgBuilding a diverse and sustainable free software ecosystemNews – The GNOME Foundation2024-04-18T17:38:23Zhttps://ondrej.holych.net/?p=117What’s new in GVfs for GNOME 46?
It has been 3 years since my last post with release news for GVfs. This is mainly because previous releases were more or less just bug fixes. In contrast, GVfs 1.54 comes with two new backends. Let’s take a look at them. OneDrive One of the backends adds OneDrive support thanks to Jan-Michael Brummer. This …
It has been 3 years since my last post with release news for GVfs. This is mainly because previous releases were more or less just bug fixes. In contrast, GVfs 1.54 comes with two new backends. Let’s take a look at them.
OneDrive
One of the backends adds OneDrive support thanks to Jan-Michael Brummer. This requires setting up a Microsoft 365 account through the Online Accounts panel in the Settings application. Then the OneDrive share can be accessed from the sidebar of the Files application.
However, creating the account is a bit tricky now. You need to register on the Microsoft Entra portal to get a client ID. The specific steps can be found in the gnome-online-accounts#308 issue. Efforts are underway to register a client ID for GNOME, so this step will soon be unnecessary.
WS-Discovery
The other backend brings WS-Discovery support. It automatically discovers the shared SMB folders of the Windows devices available on your network. You can find them in the Other Locations view of the Files application. This has not worked since the NT1 protocol was deprecated. For more information on this topic, see my previous post.
You won’t find the Windows Network folder in the Other Locations view, all the discovered shares are directly listed in the Networks section now.
Finally, I would like to thank all the GVfs contributors. Let me know in the comments if you like the new backends. I hope the next releases will also bring some great news.
2024-03-20T07:05:52Z2024-03-20T07:05:52ZOndřej Holýhttps://ondrej.holych.nethttps://ondrej.holych.net/wp-content/uploads/sites/3/2020/08/cropped-gravatar_circular_small-32x32.pngProgrammer BlogOndřej Holý2024-03-20T07:21:19Zhttps://arunraghavan.net/?p=2619Asymptotic: A 2023 ReviewIt’s been a busy few several months, but now that we have some breathing room, I wanted to take stock of what we have done over the last year or so. This is a good thing for most people and companies to do of course, but being a scrappy, (questionably) young organisation, it’s doubly important […]
It’s been a busy few several months, but now that we have some breathing
room, I wanted to take stock of what we have done over the last year or so.
This is a good thing for most people and companies to do of course, but being a
scrappy, (questionably) young organisation, it’s doubly important for us to
introspect. This allows us to both recognise our achievements and ensure that
we are accomplishing what we have set out to do.
One thing that is clear to me is that we have been lagging in writing about
some of the interesting things that we have had the opportunity to work on,
so you can expect to see some more posts expanding on what you find below, as
well as some of the newer work that we have begun.
(note: I write about our open source contributions below, but needless to say,
none of it is possible without the collaboration, input, and reviews of members of
the community)
WHIP/WHEP client and server for GStreamer
If you’re in the WebRTC world, you likely have not missed the excitement around
standardisation of HTTP-based signalling protocols, culminating in the
WHIP and
WHEP specifications.
Tarun has been driving our client and server
implementations for both these protocols, and in the process has been
refactoring some of the webrtcsink and webrtcsrc code to make it easier to
add more signaller implementations. You can find out more about this work in
his talk at GstConf 2023
and we’ll be writing more about the ongoing effort here as well.
Low-latency embedded audio with PipeWire
Some of our work involves implementing a framework for very low-latency audio
processing on an embedded device. PipeWire is a good fit for this sort of
application, but we have had to implement a couple of features to make it work.
It turns out that doing timer-based scheduling can be more CPU intensive than
ALSA period interrupts at low latencies, so we implemented an IRQ-based
scheduling mode for PipeWire. This is now used by default when a pro-audio
profile is selected for an ALSA device.
In addition to this, we also implemented rate adaptation for USB gadget devices
using the USB Audio Class “feedback control” mechanism. This allows USB gadget
devices to adapt their playback/capture rates to the graph’s rate without
having to perform resampling on the device, saving valuable CPU and latency.
There is likely still some room to optimise things, so expect to more hear on
this front soon.
This should be useful in various embedded devices that have both the hardware
and firmware to make use of this power-saving feature.
GStreamer LC3 encoder and decoder
Tarun wrote a GStreamer plugin implementing the LC3 codec
using the liblc3 library. This is the
primary codec for next-generation wireless audio devices implementing the
Bluetooth LE Audio specification. The plugin is upstream and can be used to
encode and decode LC3 data already, but will likely be more useful when the
existing Bluetooth plugins to talk to Bluetooth devices get LE audio support.
QUIC plugins for GStreamer
Sanchayan implemented a QUIC source and sink plugin in
Rust, allowing us to start experimenting with the next generation of network
transports. For the curious, the plugins sit on top of the Quinn
implementation of the QUIC protocol.
There is a merge request open
that should land soon, and we’re already seeing folks using these plugins.
AWS S3 plugins
We’ve been fleshing out the AWS S3 plugins over the years, and we’ve added a
new awss3putobjectsink. This provides a better way to push small or sparse
data to S3 (subtitles, for example), without potentially losing data in
case of a pipeline crash.
We’ll also be expecting this to look a little more like multifilesink,
allowing us to arbitrary split up data and write to S3 directly as multiple
objects.
Update to webrtc-audio-processing
We also updated the webrtc-audio-processing
library, based on more recent upstream libwebrtc. This is one of those things
that becomes surprisingly hard as you get into it — packaging an API-unstable
library correctly, while supporting a plethora of operating system and
architecture combinations.
Clients
We can’t always speak publicly of the work we are doing with our clients, but
there have been a few interesting developments we can (and have spoken about).
Both Sanchayan and I spoke a bit about our work with WebRTC-as-a-service
provider, Daily. My talk at the GStreamer Conference
was a summary of the work I wrote about previously
about what we learned while building Daily’s live streaming, recording, and
other backend services. There were other clients we worked with during the
year with similar experiences.
Sanchayan spoke about the interesting approach to building
SIP support
that we took for Daily. This was a pretty fun project, allowing us to build a
modern server-side SIP client with GStreamer and SIP.js.
An ongoing project we are working on is building AES67 support using GStreamer
for FreeSWITCH, which essentially allows
bridging low-latency network audio equipment with existing SIP and related
infrastructure.
As you might have noticed from previous sections, we are also working on a
low-latency audio appliance using PipeWire.
Retrospective
All in all, we’ve had a reasonably productive 2023. There are things I know we
can do better in our upstream efforts to help move merge requests and issues,
and I hope to address this in 2024.
We have ideas for larger projects that we would like to take on. Some of these
we might be able to find clients who would be willing to pay for. For the ideas
that we think are useful but may not find any funding, we will continue to
spend our spare time to push forward.
If you made this this far, thank you, and look out for more updates!
2024-03-19T14:54:45Z2024-03-19T14:54:45ZArunhttps://arunraghavan.netOpen source hackerf/oss – Arun Raghavan2024-03-19T14:54:45Zhttps://blogs.gnome.org/uraeus/?p=10884PipeWire camera handling is now happening!
We hit a major milestones this week with the long worked on adoption of PipeWire Camera support finally starting to land! Not long ago Firefox was released with experimental PipeWire camera support thanks to the great work by Jan Grulich. … Continue reading →
We hit a major milestones this week with the long worked on adoption of PipeWire Camera support finally starting to land!
Then this week OBS Studio shipped with PipeWire camera support thanks to the great work of Georges Stavracas, who cleaned up the patches and pushed to get them merged based on earlier work by himself, Wim Taymans and Colulmbarius. This means we now have two major applications out there that can use PipeWire for camera handling and thus two applications whose video streams that can be interacted with through patchbay applications like Helvum and qpwgraph.
These applications are important and central enough that having them use PipeWire are in itself useful, but they will now also provide two examples of how to do it for application developers looking at how to add PipeWire camera support to their own applications; there is no better documentation than working code.
The PipeWire support is also paired with camera portal support. The use of the portal also means we are getting closer to being able to fully sandbox media applications in Flatpaks which is an important goal in itself. Which reminds me, to test out the new PipeWire support be sure to grab the official OBS Studio Flatpak from Flathub.
PipeWire camera handling with OBS Studio, Firefox and Helvum.
Let me explain what is going on in the screenshot above as it is a lot. First of all you see Helvum there on the right showning all the connections made through PipeWire, both the audio and in yellow, the video. So you can see how my Logitech BRIO camera is feeding a camera video stream into both OBS Studio and Firefox. You also see my Magewell HDMI capture card feeding a video stream into OBS Studio and finally gnome-shell providing a screen capture feed that is being fed into OBS Studio. On the left you see on the top Firefox running their WebRTC test app capturing my video then just below that you see the OBS Studio image with the direct camera feed on the top left corner, the screencast of Firefox just below it and finally the ‘no signal’ image is from my HDMI capture card since I had no HDMI device connected to it as I was testing this.
The PipeWire support is of course fresh and I am sure we will find bugs and corner cases that needs fixing as more people test out the functionality in both Firefox and OBS Studio and there are some interface annoyances we are working to resolve. For instance since PipeWire support both V4L and libcamera as a backend you do atm get double entries in your selection dialogs for most of your cameras. Wireplumber has implemented de-deplucation code which will ensure only the libcamera listing will show for cameras supported by both v4l and libcamera, but is only part of the development version of Wireplumber and thus it will land in Fedora Workstation 40, so until that is out you will have to deal with the duplicate options.
Camera selection dialog
We are also trying to figure out how to better deal with infraread cameras that are part of many modern webcams. Obviously you usually do not want to use an IR camera for your video calls, so we need to figure out the best way to identify them and ensure they are clearly marked and not used by default.
Another recent good PipeWire new tidbit that became available with the PipeWire 1.0.4 release PipeWire maintainer Wim Taymans also fixed up the FireWire FFADO support. The FFADO support had been in there for some time, but after seeing Venn Stone do some thorough tests and find issues we decided it was time to bite the bullet and buy some second hand Firewire hardware for Wim to be able to test and verify himself.
Focusrite firewire device
.
Once the Focusrite device I bought landed at Wims house he got to work and cleaned up the FFADO support and make it both work and be performant.
For those unaware FFADO is a way to use Firewire devices without going through ALSA and is popular among pro-audio folks because it gives lower latencies. Firewire is of course a relatively old technology at this point, but the audio equipment is still great and many audio engineers have a lot of these devices, so with this fixed you can plop a Firewire PCI card into your PC and suddenly all those old Firewire devices gets a new lease on life on your Linux system. And you can buy these devices on places like ebay or facebook marketplace for a fraction of their original cost. In some sense this demonstrates the same strength of PipeWire as the libcamera support, in the libcamera case it allows Linux applications a way to smoothly transtion to a new generation of hardware and in this Firewire case it allows Linux applications to keep using older hardware with new applications.
So all in all its been a great few weeks for PipeWire and for Linux Audio AND Video, and if you are an application maintainer be sure to look at how you can add PipeWire camera support to your application and of course get that application packaged up as a Flatpak for people using Fedora Workstation and other distributions to consume.
2024-03-15T16:30:39Z2024-03-15T16:30:39Zuraeushttps://blogs.gnome.org/uraeusBlog talking about Fedora, GNOME, GStreamer and related topics. Anything I write in this blog is me speaking as a member of the open source community, official Red Hat communication happens on Redhat.com. The comments are my own personal opinion.Christian F.K. Schaller2024-03-28T21:56:05Zhttps://blogs.gnome.org/alicem/?p=7413Libadwaita 1.5
Well, another cycle has passed. This one was fairly slow, but nevertheless has a major new feature. Adaptive Dialogs The biggest feature this time is the new dialog widgetry. Traditionally, dialogs have been separate windows. While this approach generally works, we never figured out how to reasonably support that on mobile. There was a downstream … Continue reading Libadwaita 1.5
Well, another cycle has passed.
This one was fairly slow, but nevertheless has a major new feature.
Adaptive Dialogs
The biggest feature this time is the new dialog widgetry.
Traditionally, dialogs have been separate windows. While this approach generally works, we never figured out how to reasonably support that on mobile. There was a downstream patch for auto-maximizing dialogs, which in turn required them to be resizable, which is not great on desktop, and the patch was hacky and never really supported upstream.
Another problem is close buttons – we want to keep them in dialogs instead of needing to go to overview to close every dialog, and that’s why mobile gnome-shell doesn’t hide close buttons at all atm. Ideally we want to keep them in dialogs, but be able to remove them everywhere else.
While it would be possible to have shell present dialogs differently, another approach is to move them to the client instead. That’s not a new approach, here are some existing examples:
This has both upsides and downsides. One upside is that the toolkit/app has much more control over them. For example, it’s very easy to ensure their size doesn’t exceed the parent window. While this is possible with windows (AdwMessageDialog does this), it’s hacky and can still break fairly easily with e.g. maximize – in fact, I’m not confident it works across compositors and in both Wayland and X11.
Having dialogs not exceed the parent’s size means not needing to limit their size quite so aggressively – previously it was needed so that the dialog doesn’t get ridiculously large on top of a small window.
The dimming behind the dialog can also vary between light and dark styles – shell cannot do that because it doesn’t know if this particular window is light or dark, only what the whole system prefers.
In future this should also allow to support per-tab dialogs. For apps like web browsers, a background tab spawning a dialog that takes over the whole window is not great.
Meanwhile the main downside is the same thing as was listed in upsides: these dialogs cannot exceed the parent window’s size. Sometimes it’s still needed, e.g. if the parent window is really small.
Bottom Sheets
So, how does that help on mobile? Well, aside from just implementing the existing size constraints on AdwMessageDialog more cleanly, it allows to present these dialogs as bottom sheets on mobile, instead of centered floating sheets.
A previous design has presented dialogs as pages with back buttons, but that had many other problems, especially on small windows on desktop. For example, what happens if you close the window? A dialog and a “regular” subpage would look identical, so you’d probably expect the close button to close the entire window? But if it’s floating above a larger window?
Bottom sheets avoid this issue – you still see the parent window with its own close button, so it’s obvious that they are closed separately – while still being allowed to take full width like a subpage.
They can also be swiped down, though because of GTK limitations this does not work together with scrolling content. It’s still possible to swipe down from header bar or the empty space above the sheet.
And the fact they are attached to the bottom edge makes them easier to reach on huge phones.
Meanwhile, AdwHeaderBar always shows a close button within dialogs, regardless of the system layout. The only hint it takes from the system is whether to display the close button on the right or left side.
API
For the most part they are used similarly to GtkWindow. The main differences are with presenting and closing dialogs.
The :transient-for property has been replaced with a parameter in adw_dialog_present(). It also doesn’t necessarily take a window anymore, but can accept any widget within that window as well. Currently it just fetches the root widget, but once we have per-tab dialogs, that can be controlled with a simple flag instead of needing a new variant of adw_tab_present() that would take a tab page instead of a window.
The ::close-request signal has been replaced as well. Because the dialogs can be swiped down on mobile, we need to know if they can be closed before the gesture starts. So, instead there’s a :can-close property that apps set ahead of time if there’s unsaved data or some other reason to prevent closing.
For close confirmation, there’s a ::close-attempt signal, which will be fired when trying to close a dialog using a close button or a shortcut while :can-close is set to FALSE (or calling adw_dialog_close()). For actual closing, there’s ::closed instead.
Finally, adw_dialog_force_close() closes the dialog while ignoring :can-close. It can be used to close the dialog after confirmation without needing to fiddle with :can-close or repeat ::close-attempt emissions.
If this works well, AdwWindow may have something similar in future.
The rest is fairly straightforward and is modelled after GtkWindow. See AdwDialog docs and migration guide for more details.
Since AdwPreferencesWindow and other widgets can’t be ported to new dialogs without a significant API break, they have been replaced:
For the most part they are identical, with a few differences:
AdwPreferencesDialog has search disabled by default, and gets rid of deprecated subpage API
AdwAlertDialog can scroll contents, so apps that add their own scrolled windows may want to remove them
Since the new widgets landed right at the end of the cycle, the old widgets are not deprecated yet. However, they will be deprecated next cycle, so it’s recommended to migrate your apps anyway.
Standalone bottom sheets (like in audio players) are not available yet either, but will be in future.
Esc to Close
Traditionally, dialogs have been done via GtkDialog which handled this automatically. But for the last few years, apps have been steadily moving away from GtkDialog and by now it’s deprecated. While that’s not really a problem on its own, one thing that GtkDialog was doing automatically and custom dialogs don’t is closing when pressing Esc. While it’s pretty easy to add that manually, a lot of apps forget to do so.
But since we have dedicated dialog API again, Esc to close is once again automatic.
What about standalone dialogs?
Some dialogs don’t have a parent window. Those are still presented as a window. Note that it still doesn’t work well on mobile: while there will be a close button, the sizing will work just as badly as before, so it’s recommended to avoid them.
Dialogs will also be presented as a window if you try to ad them to a parent that can’t host dialogs (anything that’s not an AdwWindow or AdwApplicationWindow), or the parent is not resizable. The reason for the last one is to accommodate apps like Emblem, which has a small non-resizable window, where dialogs won’t fully fit, and since it’s non-resizable, it doesn’t work on mobile anyway.
What about “Attach Modal Dialogs”
Since we have the window-backed mode, it would be fairly easy to support that preference… except there’s no way to read it from sandboxed apps.
What about portals?
This approach obviously doesn’t work for portals, since they are in a separate process. We do have a plan for them, involving a private protocol in mutter, but it didn’t make it for 46. So, next time.
What about GTK built-in dialogs?
Those will be replaced as well, but it takes time. For now yes, GtkShortcutsWindow etc won’t match other dialogs.
AdwBreakpointBin now allows to programmatically remove breakpoints.
AdwSwipeTracker now has a flag to allow swiping over header bars – used in bottom sheets.
Shade colors are now lighter in dark style. This was needed for dialog dimming to look good, but also it was previously too dark elsewhere, e.g. in scroll undershoots.
As always, thanks to all the contributors who helped to make this release happen.
2024-03-15T15:58:48Z2024-03-15T15:58:48ZAlice Mikhaylenkohttps://blogs.gnome.org/alicemAlice Mikhaylenko's GNOME blogJust another blog2024-03-18T13:24:35Ztag:blogger.com,1999:blog-5620128670216603593.post-1333086758446229630Maps and GNOME 46
It's that time again, a new GNOME release is just around the corner.
The news in Maps for GNOME 46
A lot of the new things we've been working on for the 46 release has already been covered, but here is few recaps.
The new map style
The map style used for the vector-based, client-side rendered map which is still considered experimental in 46 has been switched over to our new “GNOME-themed” style, which also supports a dark mode (enabled when the global dark mode is enabled).
The vector map still needs to be explicitly enabled via the “layers menu” (the second headerbar button from the left). This also require the backing installation of libshumate to be built with vector renderer support (which is the case when using the Flatpak from Flathub, and also libshumate will default to building the vector renderer from the 1.2.0 release, so distributions should likely have it enabled in their 46 installations).
The current plan looks like we're leaning towards flipping it on by default after the 46 release, so by 47 it will probably mean the old raster tiles from openstreetmap.org will be retired.
Also icons on the map (such as POIs) are now directly clickable. And labels should be localized to the user's language (when the appropriate language tags are available in the OpenStreetMap data).
Other visual improvements
For 46 the zoom control buttons has been revamped (again), and put in the lower corner (as also shown in the above screenshots):
The pin used to marked places selected from search results, and other things like pin-pointed locations in GeoJSON files has gained a new modernized design by Jakub Steiner.
The dialog for adding an OpenStreetMap account to edit POIs gained a refresh sporting the new libadwaita dialog and widgets by Felipe Kinoshita.
Also information about which floor a place is located at is shown in the place bubbles when available. This can be useful to find your way around for example big shopping malls and the like (this was an idea that came when looking for a café in a galleria in Riga last summer…).
The favorites menu has also gotten a revamp. Instead of just showing a greyed-out inactive button when there's no favored places it now has an “empty state” hinting on the ability to “star” places.
And favorites can be removed directly from the list without having to open them (and animate to that place to show the bubble).
Looking further on
For the next cycle aside from continuing the refinements to the new map style and making the vector map the main thing another cool project that was initiated during FOSDEM in Februari has caught my attention:
It is using the MOTIS project (https://github.com/motis-project/motis) as the backend, with a cround sourcing approach to collect data feeds for timetable data.
The routing can already be tested out at https://transitous.org. Currently it only handles “station to station” routing, so there is not yet support for walking instructions.
Also, unlike the current public transit plugins support we have in Maps with Transitous you would also be able to cross-border planning (utilizing timetables from different data feeds).
When it becomes a bit more mature we should make use of it in Maps ☺.
So this another area to help out by creating PRs for adding transit schedule feeds for your local area that could potentially benefit both Maps and other FOSS projects (such as KDE Itinerary).
Problems ahead
And now to something of a problem.
The location service backend that we are using (not just used by Maps, but also other parts like Weather, automatic timezone handling) GeoClue has been using Mozilla's location service API (MLS). This will unfortunately be retired https://github.com/mozilla/ichnaea/issues/2065
Maybe in worst case, we'd have to disable showing current location in Maps unless the device has an actual GPS unit.
2024-03-15T12:35:00Z2024-03-15T12:35:00ZMarcus Lundbladnoreply@blogger.comhttp://www.blogger.com/profile/02923955229568787222tag:blogger.com,1999:blog-5620128670216603593Marcus Lundbladnoreply@blogger.comhttp://www.blogger.com/profile/02923955229568787222The Maps and Geo Blog2024-03-18T21:01:59Zhttps://mjg59.dreamwidth.org/69507.htmlDigital forgeries are hard
Closing arguments in the trial between various people and Craig Wright over whether he's Satoshi Nakamoto are wrapping up today, amongst a bewildering array of presented evidence. But one utterly astonishing aspect of this lawsuit is that expert witnesses for both sides agreed that much of the digital evidence provided by Craig Wright was unreliable in one way or another, generally including indications that it wasn't produced at the point in time it claimed to be. And it's fascinating reading through the subtle (and, in some cases, not so subtle) ways that that's revealed.
One of the pieces of evidence entered is screenshots of data from Mind Your Own Business, a business management product that's been around for some time. Craig Wright relied on screenshots of various entries from this product to support his claims around having controlled meaningful number of bitcoin before he was publicly linked to being Satoshi. If these were authentic then they'd be strong evidence linking him to the mining of coins before Bitcoin's public availability. Unfortunately the screenshots themselves weren't contemporary - the metadata shows them being created in 2020. This wouldn't fundamentally be a problem (it's entirely reasonable to create new screenshots of old material), as long as it's possible to establish that the material shown in the screenshots was created at that point. Sadly, well.
One part of the disclosed information was an email that contained a zip file that contained a raw database in the format used by MYOB. Importing that into the tool allowed an audit record to be extracted - this record showed that the relevant entries had been added to the database in 2020, shortly before the screenshots were created. This was, obviously, not strong evidence that Craig had held Bitcoin in 2009. This evidence was reported, and was responded to with a couple of additional databases that had an audit trail that was consistent with the dates in the records in question. Well, partially. The audit record included session data, showing an administrator logging into the data base in 2011 and then, uh, logging out in 2023, which is rather more consistent with someone changing their system clock to 2011 to create an entry, and switching it back to present day before logging out. In addition, the audit log included fields that didn't exist in versions of the product released before 2016, strongly suggesting that the entries dated 2009-2011 were created in software released after 2016. And even worse, the order of insertions into the database didn't line up with calendar time - an entry dated before another entry may appear in the database afterwards, indicating that it was created later. But even more obvious? The database schema used for these old entries corresponded to a version of the software released in 2023.
This is all consistent with the idea that these records were created after the fact and backdated to 2009-2011, and that after this evidence was made available further evidence was created and backdated to obfuscate that. In an unusual turn of events, during the trial Craig Wright introduced further evidence in the form of a chain of emails to his former lawyers that indicated he had provided them with login details to his MYOB instance in 2019 - before the metadata associated with the screenshots. The implication isn't entirely clear, but it suggests that either they had an opportunity to examine this data before the metadata suggests it was created, or that they faked the data? So, well, the obvious thing happened, and his former lawyers were asked whether they received these emails. The chain consisted of three emails, two of which they confirmed they'd received. And they received a third email in the chain, but it was different to the one entered in evidence. And, uh, weirdly, they'd received a copy of the email that was submitted - but they'd received it a few days earlier. In 2024.
And again, the forensic evidence is helpful here! It turns out that the email client used associates a timestamp with any attachments, which in this case included an image in the email footer - and the mysterious time travelling email had a timestamp in 2024, not 2019. This was created by the client, so was consistent with the email having been sent in 2024, not being sent in 2019 and somehow getting stuck somewhere before delivery. The date header indicates 2019, as do encoded timestamps in the MIME headers - consistent with the mail being sent by a computer with the clock set to 2019.
But there's a very weird difference between the copy of the email that was submitted in evidence and the copy that was located afterwards! The first included a header inserted by gmail that included a 2019 timestamp, while the latter had a 2024 timestamp. Is there a way to determine which of these could be the truth? It turns out there is! The format of that header changed in 2022, and the version in the email is the new version. The version with the 2019 timestamp is anachronistic - the format simply doesn't match the header that gmail would have introduced in 2019, suggesting that an email sent in 2022 or later was modified to include a timestamp of 2019.
This is by no means the only indication that Craig Wright's evidence may be misleading (there's the whole argument that the Bitcoin white paper was written in LaTeX when general consensus is that it's written in OpenOffice, given that's what the metadata claims), but it's a lovely example of a more general issue.
Our technology chains are complicated. So many moving parts end up influencing the content of the data we generate, and those parts develop over time. It's fantastically difficult to generate an artifact now that precisely corresponds to how it would look in the past, even if we go to the effort of installing an old OS on an old PC and setting the clock appropriately (are you sure you're going to be able to mimic an entirely period appropriate patch level?). Even the version of the font you use in a document may indicate it's anachronistic. I'm pretty good at computers and I no longer have any belief I could fake an old document.
(References: this Dropbox, under "Expert reports", "Patrick Madden". Initial MYOB data is in "Appendix PM7", further analysis is in "Appendix PM42", email analysis is "Sixth Expert Report of Mr Patrick Madden")


 Many years ago, when working at Xamarin, where we were building cross-platform
libraries for mobile developers, we wanted to offer both 2D and 3D gaming
capabilities for our users in the form of adding 2D or 3D content to their
mobile applications.
Many years ago, when working at Xamarin, where we were building cross-platform
libraries for mobile developers, we wanted to offer both 2D and 3D gaming
capabilities for our users in the form of adding 2D or 3D content to their
mobile applications.
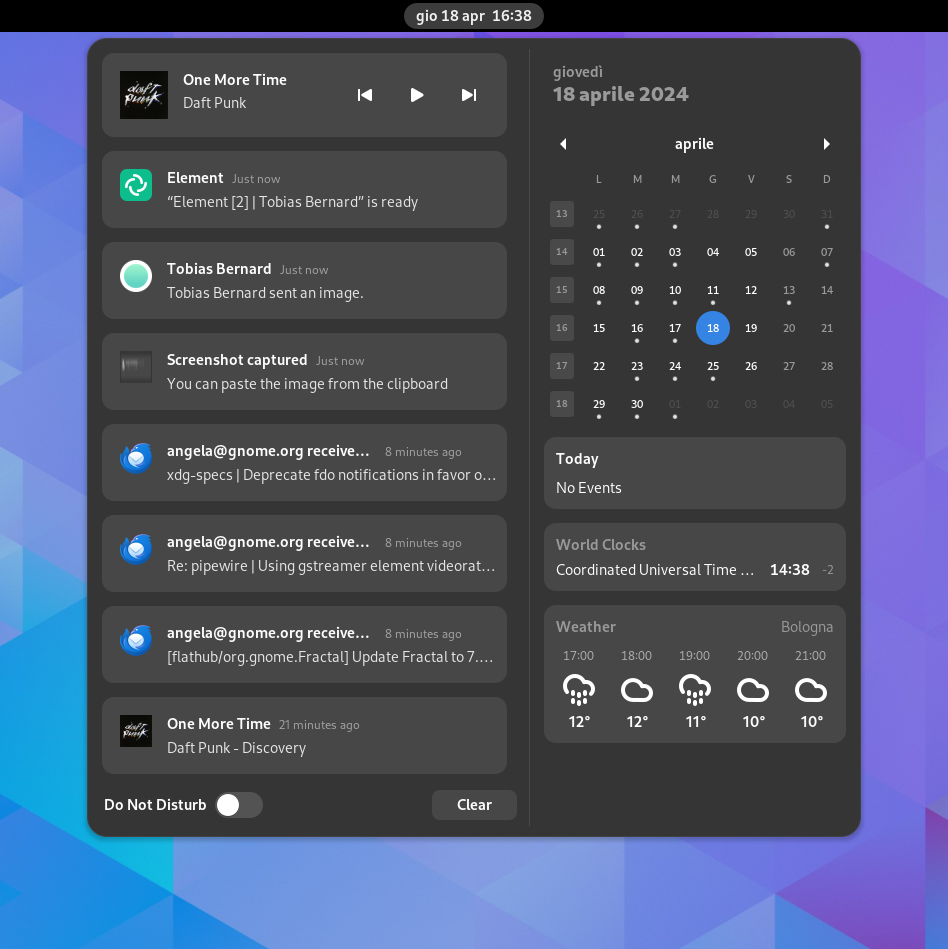
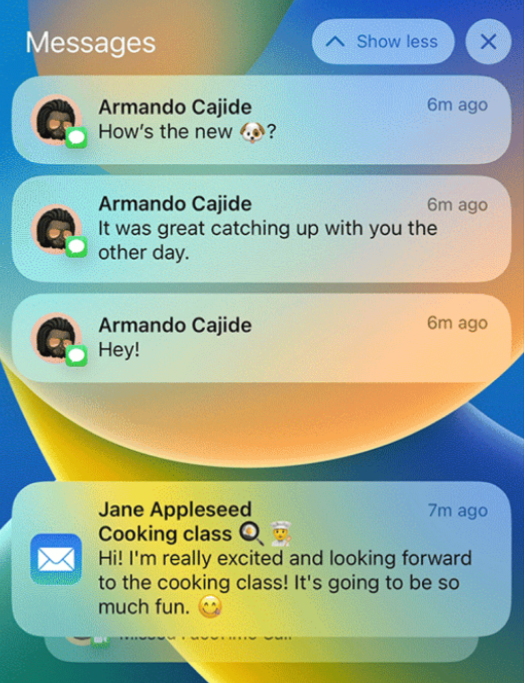
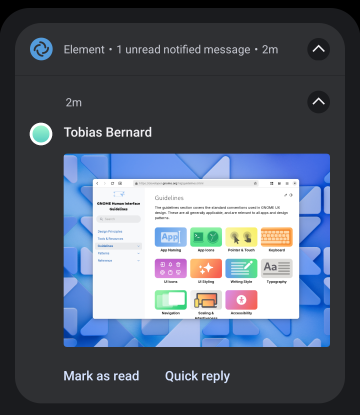
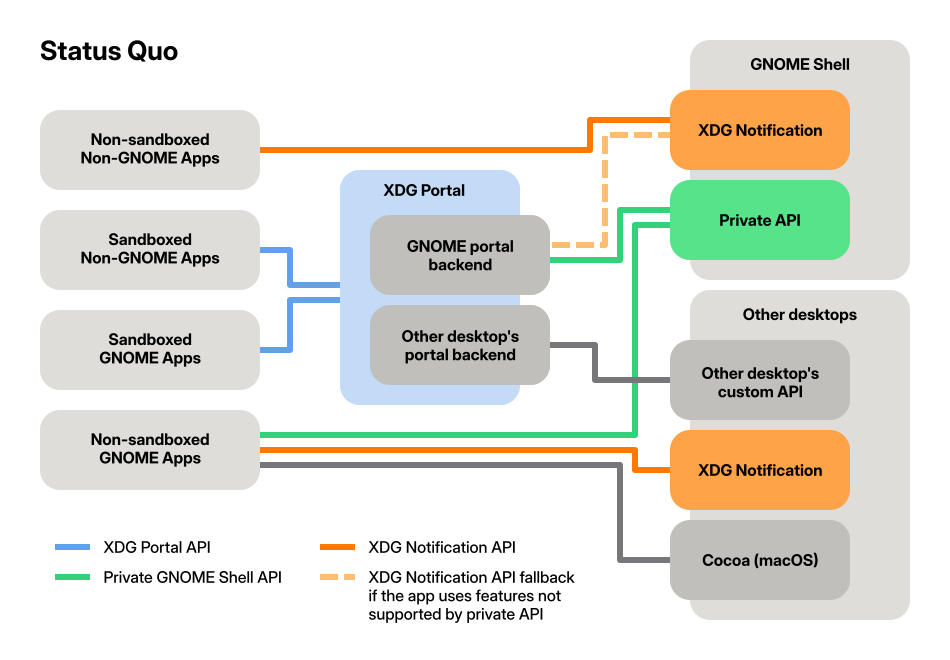
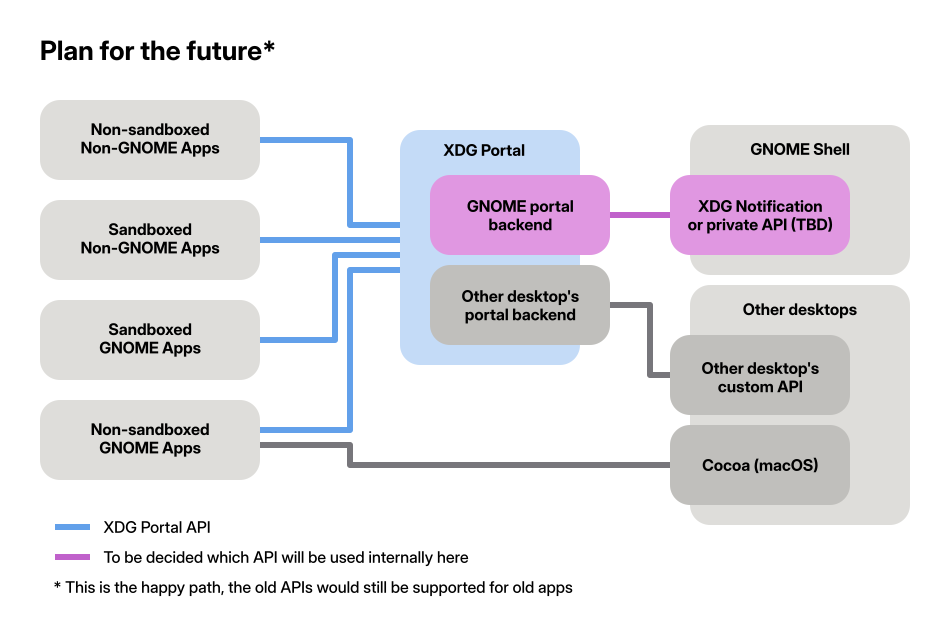







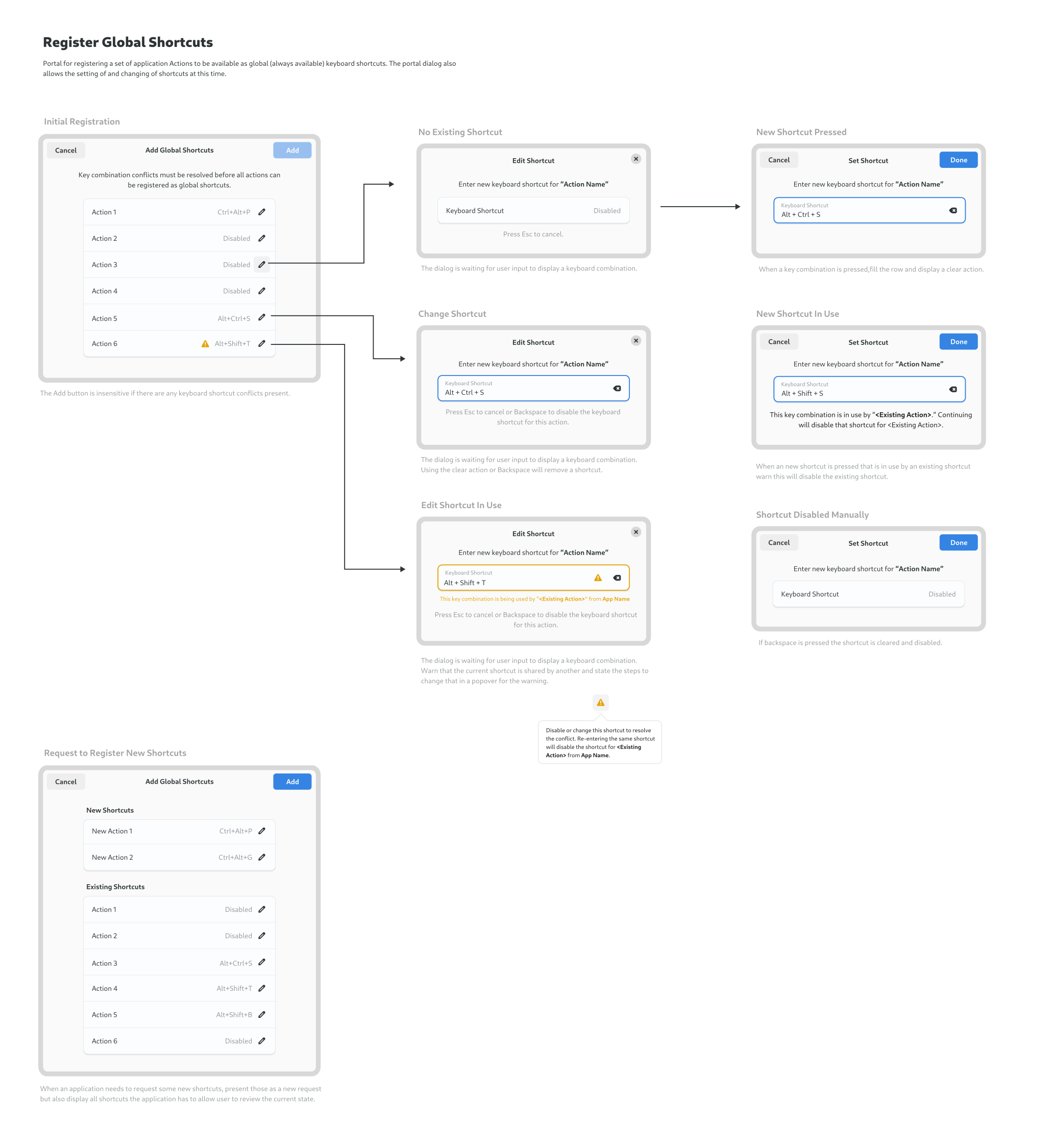
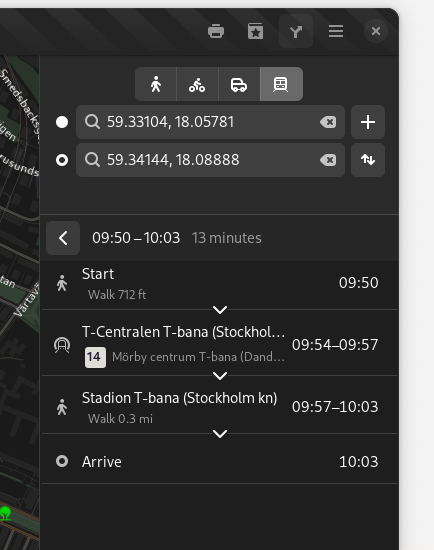
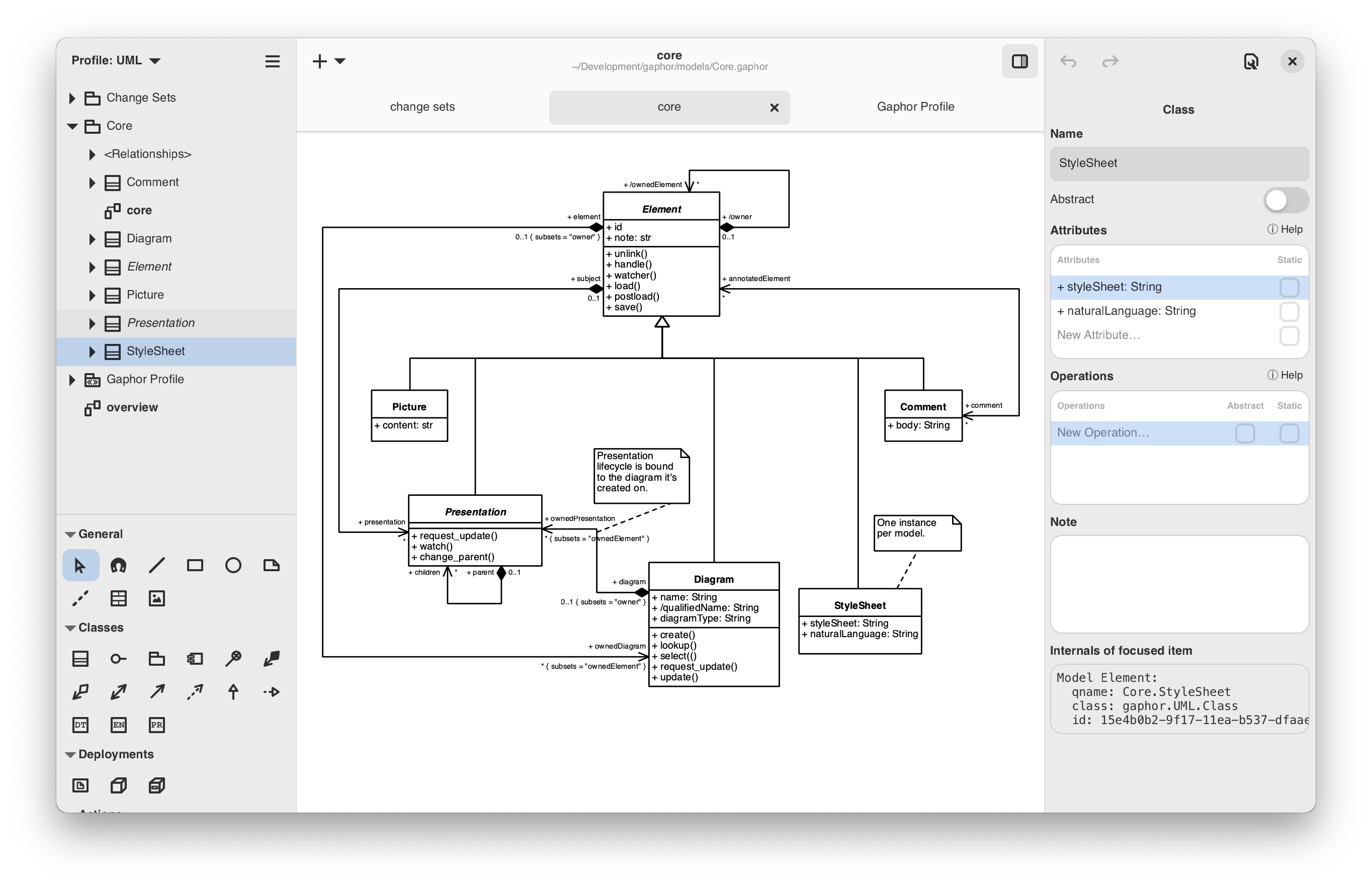


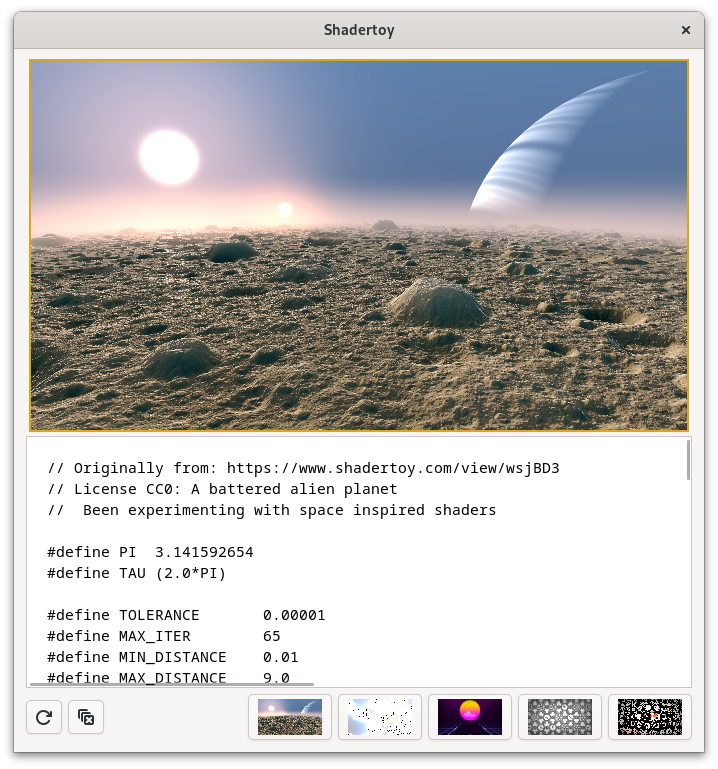




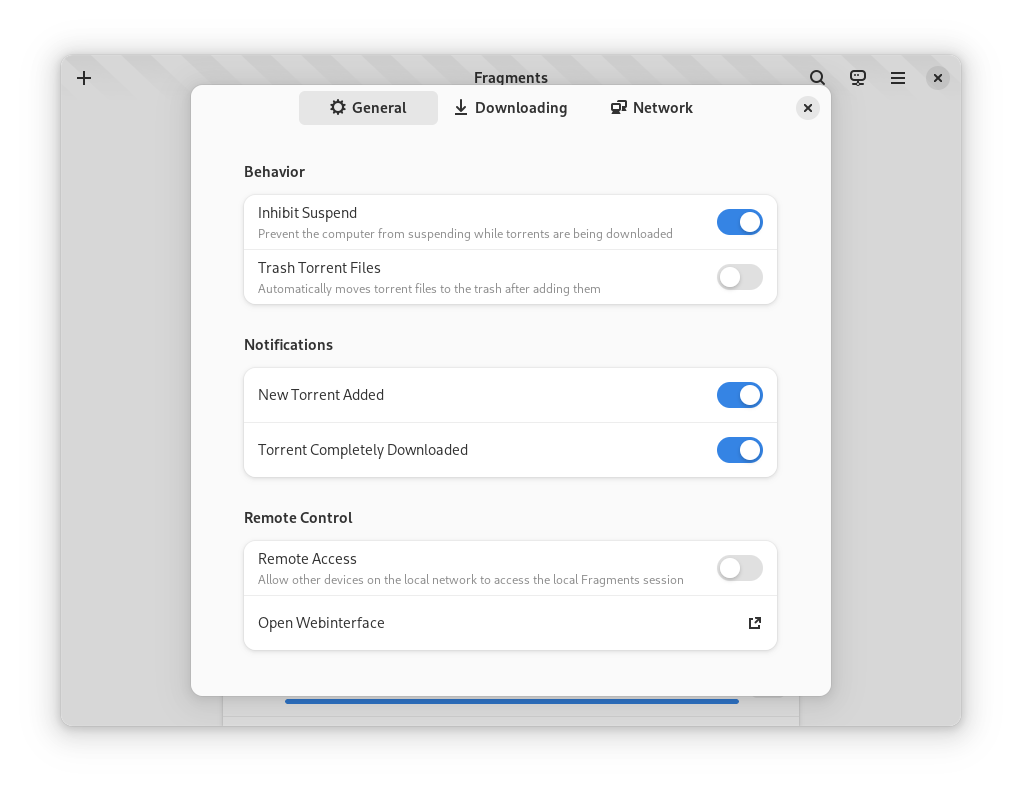

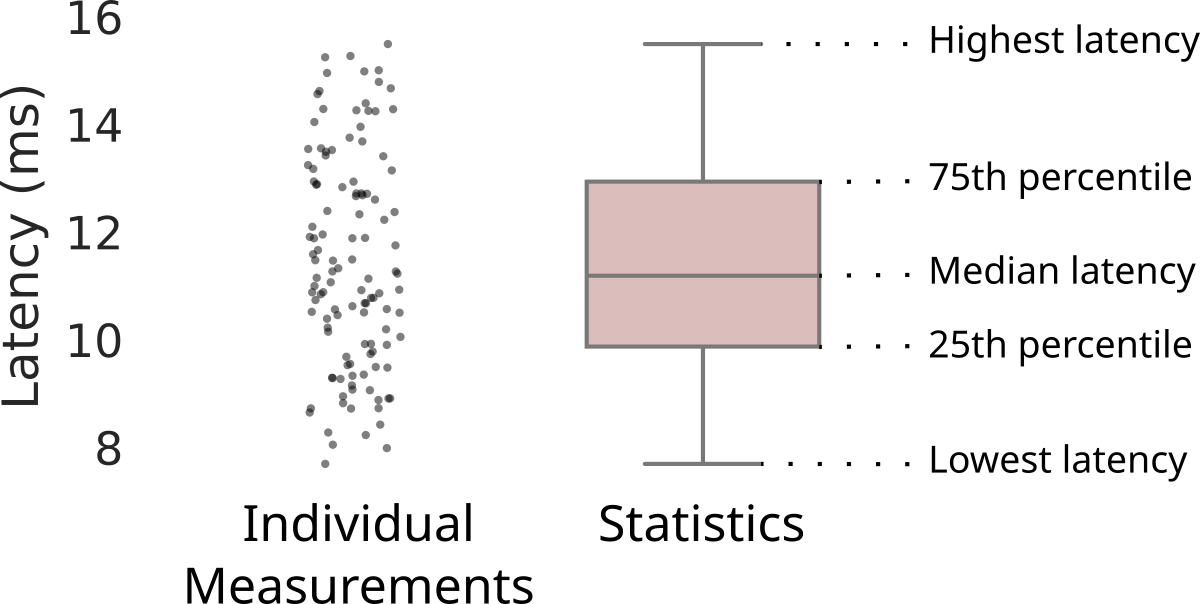
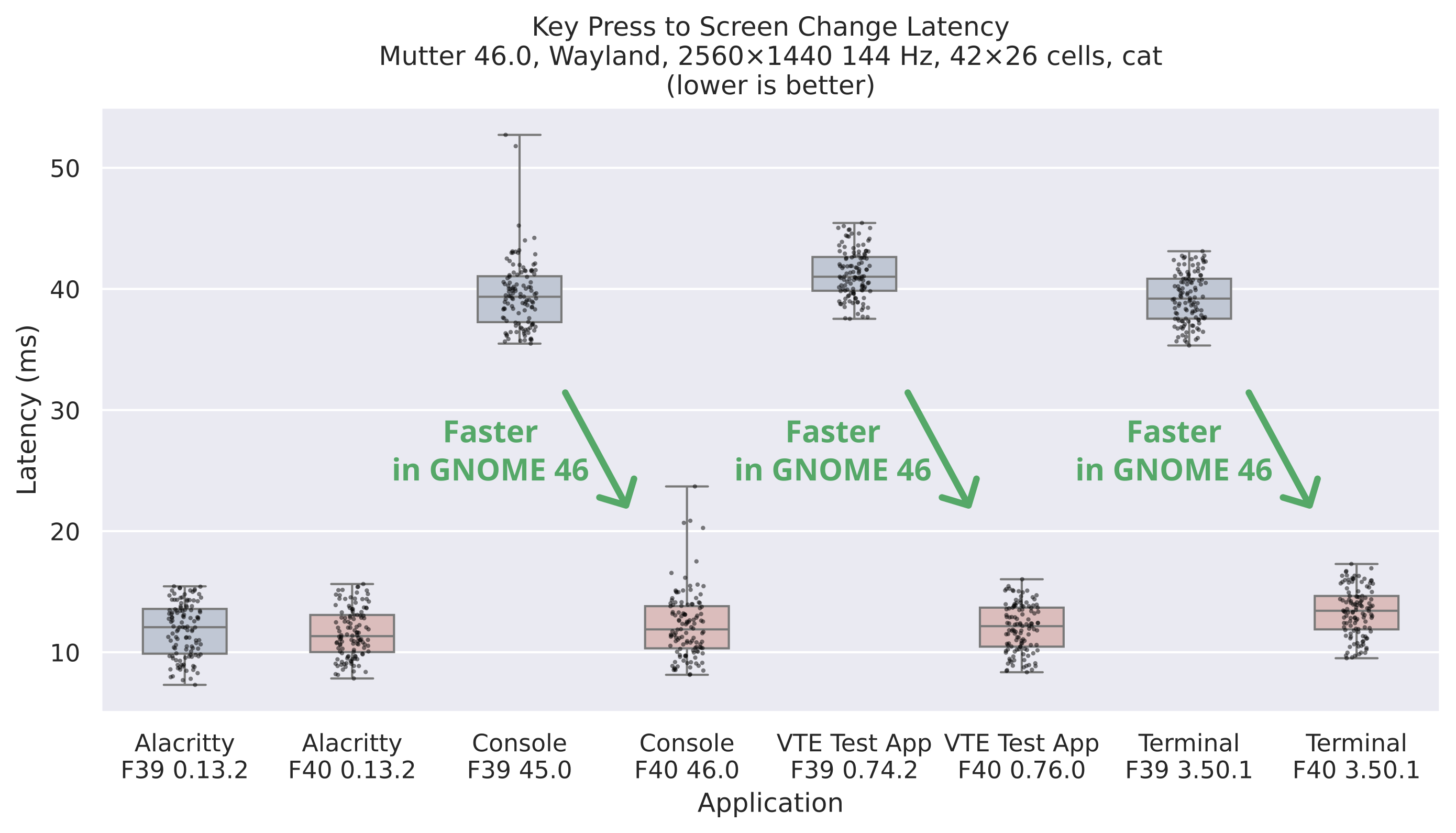
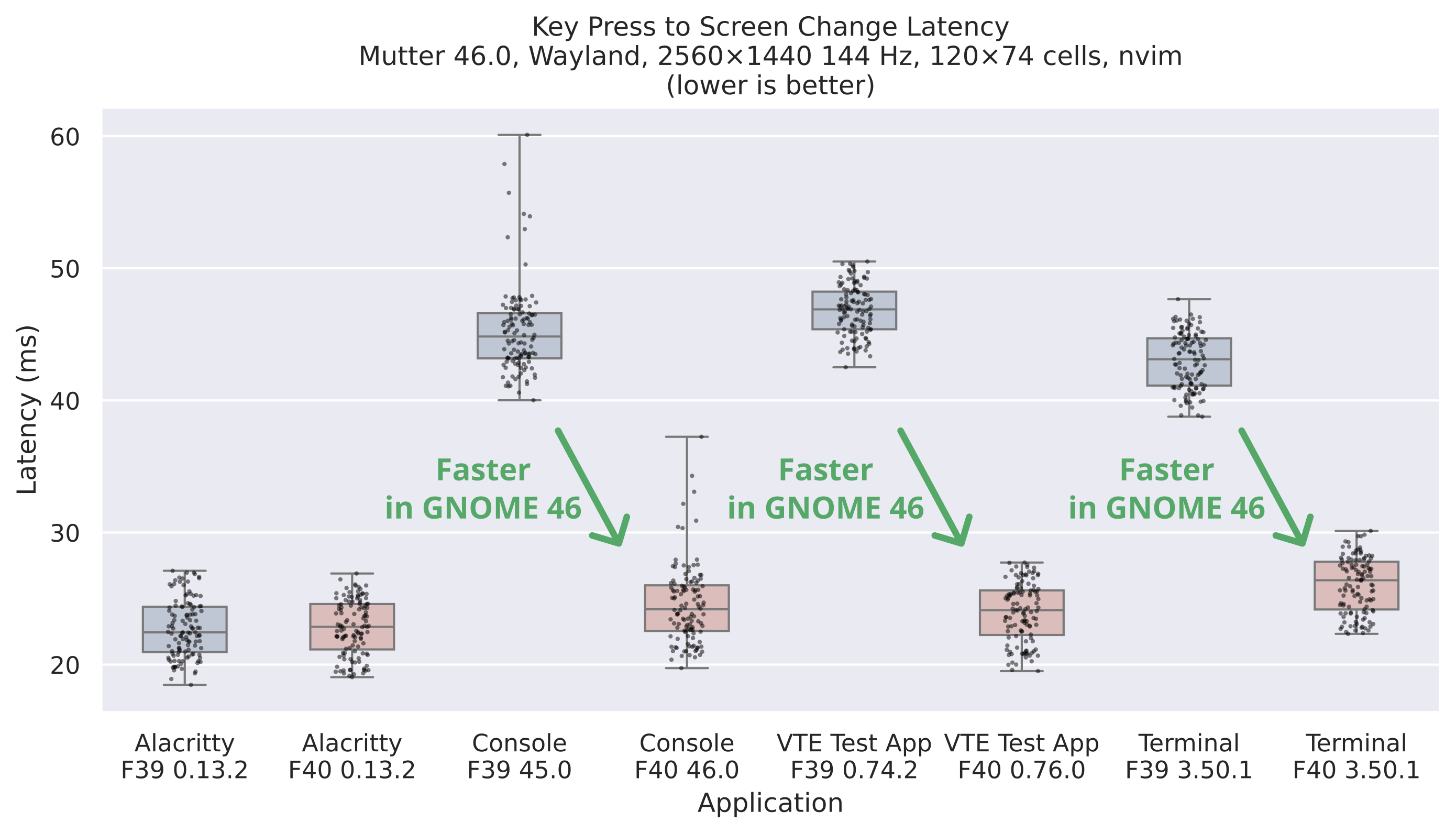
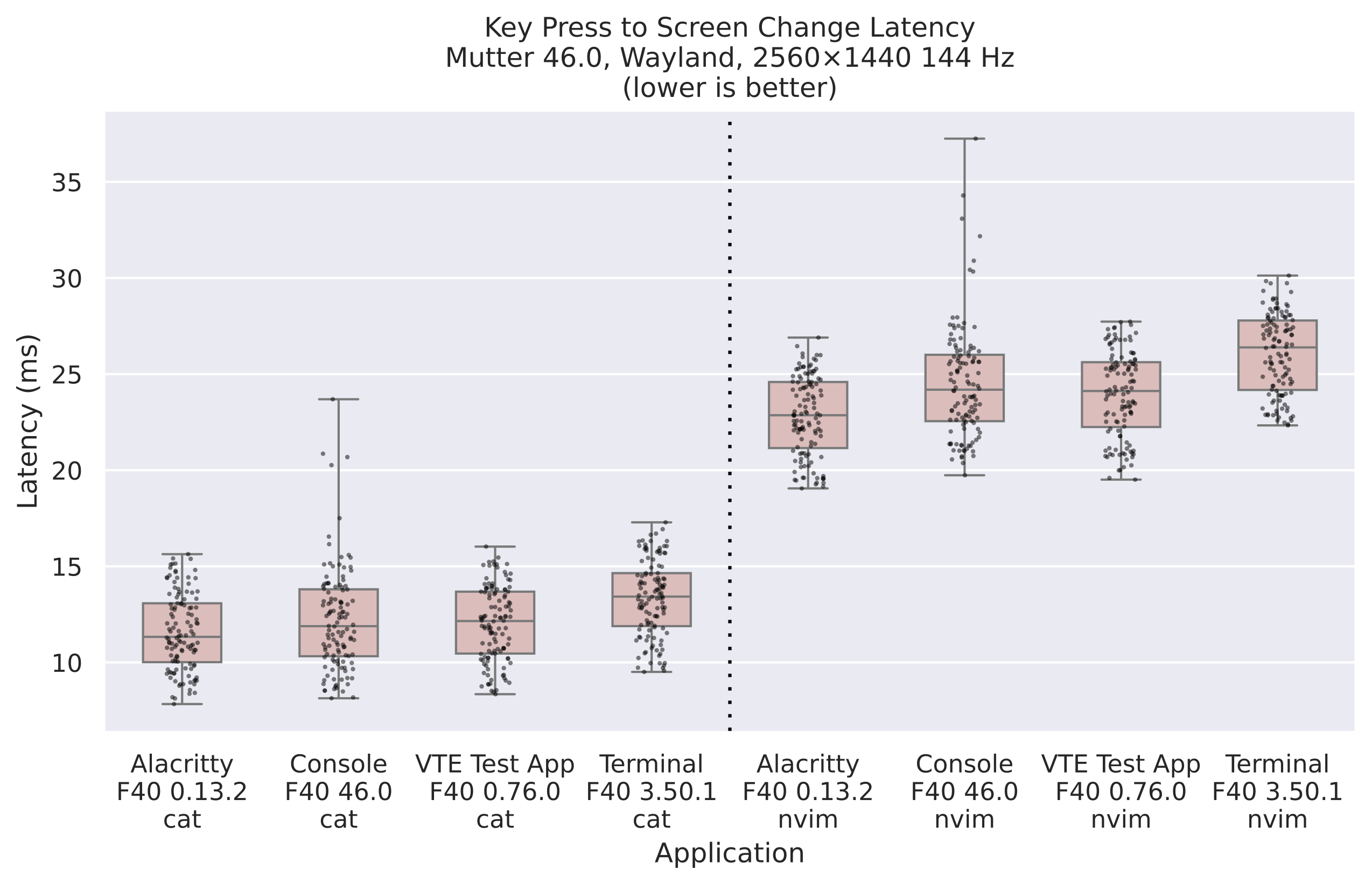

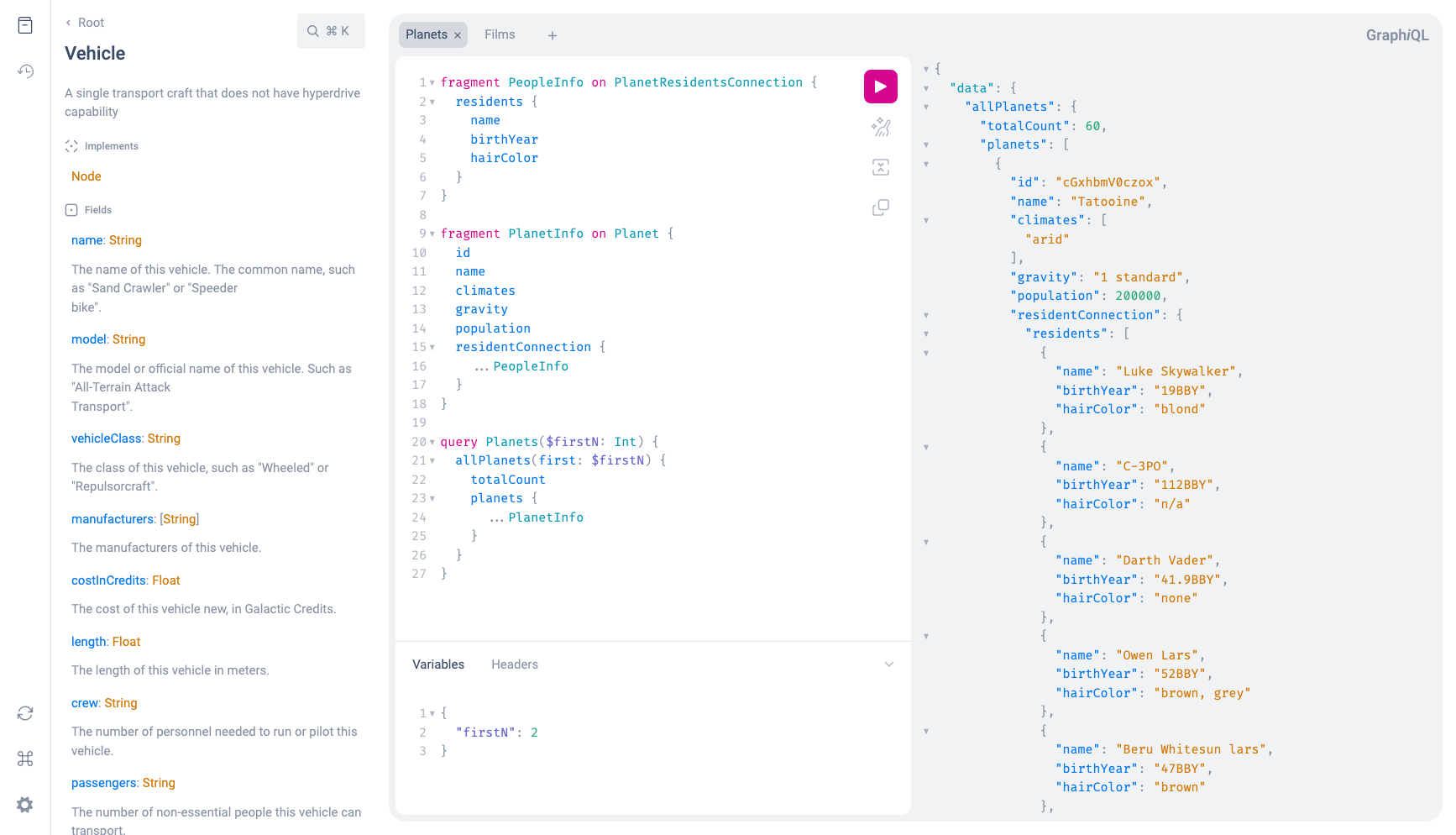












{kind=link}
{kind=link}